0 引言
2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] 。随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题。综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] 。因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义。
发热量反映了单位质量煤炭完全燃烧时所能释放的能量,是衡量煤炭品质的重要指标,也是动力用煤计价的主要依据。因此,对于发热量的高效准确测量成为了重要的研究课题。
目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] 。但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性。近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] 。
随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型。谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力。焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算。李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优。
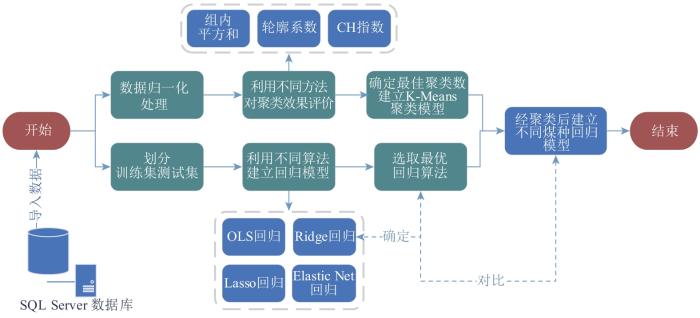
鉴于煤的全元素分析需要专业设备、耗时较长、成本较高[15 ] ,因此多数煤场一般只进行煤的工业分析和硫元素、氢元素分析[16 ] ,这给发热量的预测造成了一定程度的阻碍。煤炭工业分析具有操作简单、成本低廉、响应时间快的特点,本文依据煤种的工业分析数据,利用K-Means聚类算法对全部批次煤炭进行分类,并采用多元线性回归算法,对性质相似的煤种分别建立发热量关于工业分析数据的预测模型,实现对发热量更高精度的预测。
1 煤样情况
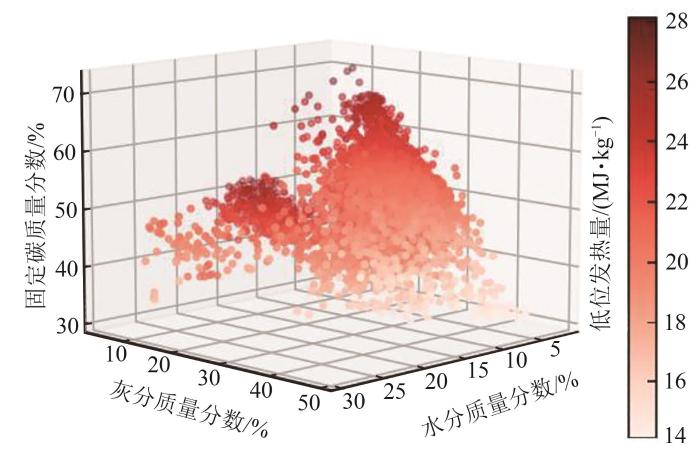
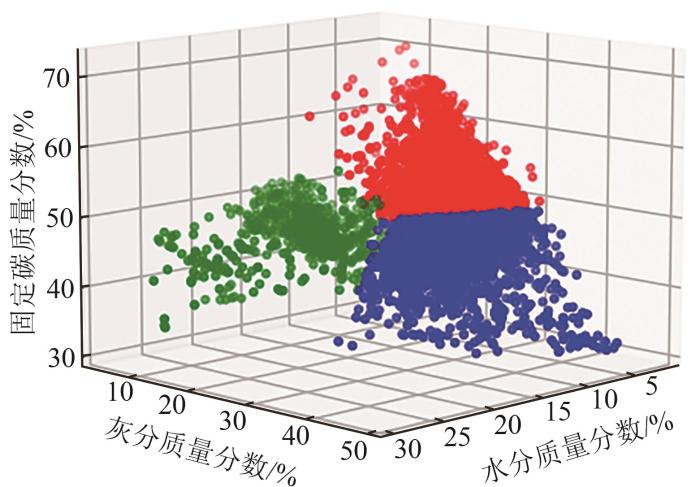
本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地。煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中。本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型。由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量。有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量。经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示。
图1
图1
样本数据的分布情况
Fig. 1
Distribution of the sample data
2 K-Means聚类算法
2.1 数据归一化
在K-Means聚类算法中,需要采用数据归一化方法减小数据中较大和较小的初始数据所占距离比重对聚类效果的影响,提高模型的收敛速度和计算精度[20 ] 。数据归一化是将数据按比例缩放,针对一个数据维度中全部数据范围缩放至[0,1]的操作。由此可以降低由于数据的量纲不同或量级差距大对模型的不良影响。本文采用最大-最小值归一化算法,对数据进行归一化处理,用公式表示其原理如下:
x ' = x - x m i n x m a x - x m i n (1)
式中:x ' x 为归一化前原始数据;x max 为数据最大值;x min 为数据最小值。
K-Means算法是一种源于信号处理的向量量化方法,现在则更多地用在聚类分析中,并广泛应用于数据挖掘领域[21 ] ,是一种经典的分割式分群聚类算法。该算法主要目标是将样本中N 个点按照相似度聚集到k 个聚簇当中,将每个点都分配到离他最近的均值(即聚类中心)对应的聚簇,以之作为聚类的标准。最终,簇内相似度高,簇间相似度低,从而完成聚类。
K-Means算法采用了迭代优化的思想,通常被称为劳埃德算法[22 ] 。该算法可分为4个步骤:
1)选择初始质心。已知共有n 条数据,每个元素都是d 维向量,全部数据集合为X ,确定聚类簇数k ,将全部数据随机分为k 个集合,故有X =X 1 ∪X 2 ∪…∪Xk ,每个集合内元素个数为Ni ,并从每个子集中随机选择一个初始聚类中心m =(m 1 , m 2 , …, mk )。
2)初始化完成后,将每个样本观测值x mi 的欧氏距离平方和,将该值命名为组内平方和(within-cluster sum of squares,WCSS),其表达式为
W C S S = ∑ i = 1 k ∑ x ∈ X i x - m i 2 (2)
3)对先前各个聚簇内所有样本分别取平均值,将其设定为新的质心mi * ,质心公式为
m i * = 1 N i ∑ x ∈ X 1 x (3)
4)计算旧质心和新质心之间的欧氏距离。算法重复最后2个步骤,直到分配方案不再改变,此时可认为算法达到收敛,组内平方和不再减小,质心不再显著移动,数值上表现为最新一次迭代所获得的质心与上一次迭代所获得的质心间的欧氏距离小于给定阈值。
2.2 最佳聚类数的选取方法
K-Means算法是一种非监督学习算法[23 ] ,聚类不需要对数据进行训练和学习,而是人为规定聚类数,再通过聚类分析将数据聚合成几个群体。不同的聚类数对最终聚类效果有很大的影响,所以需要采用评价指标辅助确定最佳聚类数,以下是评价聚类效果的3种常用方法。
2.2.1 手肘法
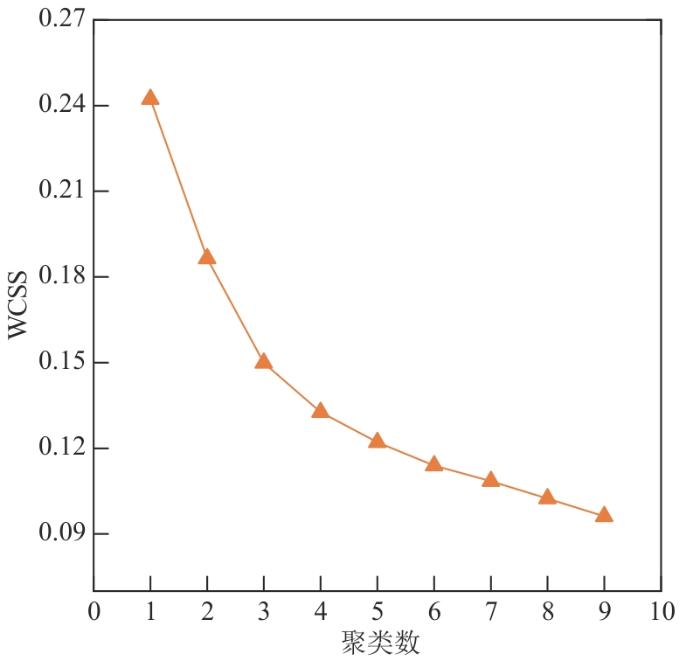
在聚类分析中,手肘法是一种用于确定数据集中聚类数量的方法,由美国心理测量学家罗伯特⋅拉德⋅桑代克于1953年首次提出[24 ] ,其原理是:设定聚类范围,随着聚类簇数k 的增大,样本划分会更加细致,每个簇的聚合程度会逐渐提高,那么WCSS自然会逐渐变小。当k 值小于最佳聚类簇数时,k 值的不断增大会使每个簇的聚合程度大幅度增加,故WCSS的下降幅度会很大。当k 到达最佳聚类数时,再增加k 所得到的聚合程度会迅速变小,组内平方和的数值变化也趋于平缓。WCSS与k 的关系图是近似于手肘的形状,而这个肘部对应的k 值就是数据的最佳聚类数[25 ] 。
图2 是不同聚类数对应的WCSS值,在聚类数k 为3时,该点的斜率变化率(前后2段折线斜率比值)最大,此时WCSS值变化最为剧烈,因此将模型聚类数设定为3最为合理。
图2
图2
手肘法判断最佳聚类数
Fig. 2
Elbow method to determine the optimal number of clustering
2.2.2 轮廓系数法
在机器学习与数据挖掘领域,轮廓系数法是一种反映数据聚类结果一致性的方法,可以用于评估聚类后簇与簇之间的离散程度[26 ] 。
对于某一个属于簇Ci 的样本i ,记为i ∈Ci ,设d (i , j )为样本i 与j 之间的欧式距离,并求算样本i 与簇内其他样本之间的平均距离,将其命名为凝聚度,记为a (i ),它反映了样本i 当前聚类结果的优劣,公式定义如下:
a ( i ) = 1 C i - 1 ∑ j ∈ C i , i ≠ j d ( i , j ) (4)
然后定义样本i 与其他簇Ck 全部样本之间的平均距离,将最小平均距离命名为分离度,记作b (i ):
b ( i ) = m i n k ≠ i 1 C k ∑ j ∈ C k d ( i , j ) (5)
s ( i ) = b ( i ) - a ( i ) m a x { a ( i ) , b ( i ) } (6)
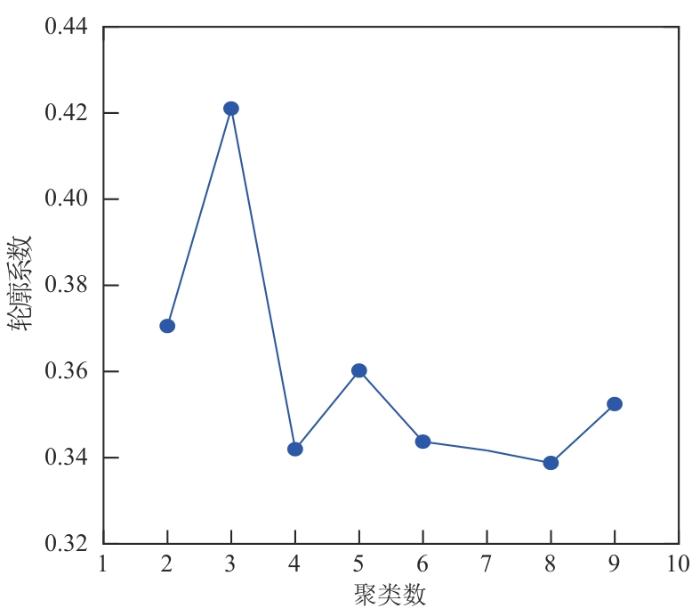
当轮廓系数达到最大值时,可认为对应k 值为最佳聚类数。图3 为不同聚类数对应的轮廓系数值,当k 值为3时,轮廓系数取值最大,对于本研究数据情况,将模型聚类数设定为3最为合理。
图3
图3
轮廓系数法判断最佳聚类数
Fig. 3
Silhouette coefficient method to determine the optimal number of clustering
2.2.3 卡林斯基-哈拉巴斯指数法
卡林斯基-哈拉巴斯(Calinski-Harabasz,CH)指数是由Calinski和Harabasz于1974年引入的一种可用于在非监督学习中评估聚类模型的指标[27 ] 。CH指数(也称为方差比标准)通过计算所有集群的集群间离散度总和与集群内离散度总和的比率来对聚类效果进行评价,其定义如下:
C H ( k ) = T r ( B k ) T r ( W k ) × N - k k - 1 (7)
W k = ∑ i = 1 k ∑ x ∈ X i ( x - m i ) ( x - m i ) T (8)
B k = ∑ i k n i ( m i - m 0 ) ( m i - m 0 ) T (9)
式中: B k W k N 为全部样本数;ni 表示i 类中的样本数; m 0 表示数据集的中心点。
当CH指数达到最大时,说明模型用尽量少的类别聚类了尽可能多的样本,因此聚类效果最优,与之对应的簇数即为最佳聚类数。
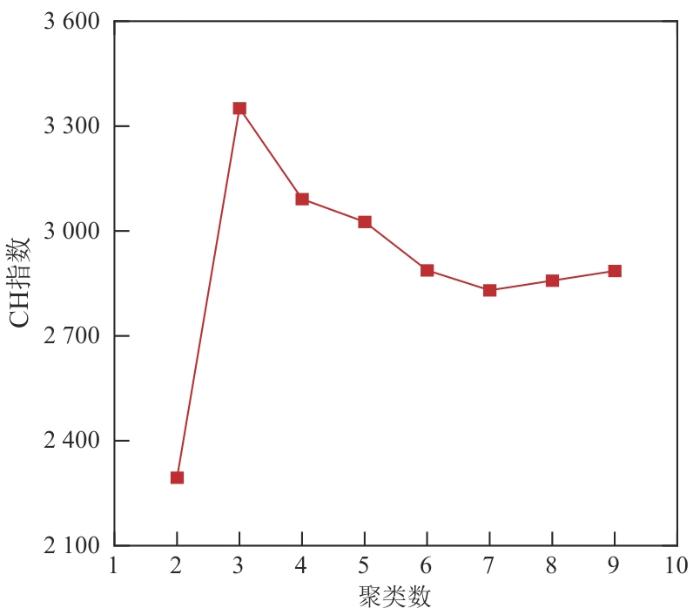
图4 是不同聚类数对应的CH指数值,在k 值为3时,CH指数值最大,因此针对本研究,将模型聚类数设定为3最为合理。
图4
图4
卡林斯基-哈拉巴斯系数法判断最佳聚类数
Fig. 4
Calinski-Harabasz index method to determine the optimal number of clustering
2.3 K-Means聚类模型的构建
根据2.2节研究,可以确定最佳聚类数k 为3。入场煤M ar 、A ar 以及F C,ar 经过归一化后,利用K-Means算法进行聚类分析。将聚类结果利用Python中Axes3D模块绘制出三维图像,最终聚类结果如图5 所示。根据聚类结果图像,可将红色簇内的煤种命名为高固定碳煤,蓝色簇内的煤种命名为高灰分煤,绿色簇内的煤种命名为高水分煤。3类煤的参数范围如表2 所示。
图5
图5
入场煤聚类结果
Fig. 5
Clustering results for the coal entered the yard
3 多元线性回归模型
3.1 基本原理
回归是监督学习的一个典型问题,可以用于预测输入变量和输出变量之间的关系[28 ] 。输出变量的值随输入变量值的变化而变化,回归模型正是表示从输入变量到输出变量映射的函数。
在统计学中,线性回归是利用线性回归方程的最小平方函数对一个或多个自变量(输入变量)和因变量(输出变量)之间关系进行建模的一种回归分析[29 ] 。其中,大于一个自变量情况的叫作多元线性回归分析[30 ] ,其基本原理如下:
对于一个有n 个输入变量的样本i 而言,回归目标函数为
y i = ω 0 + ω 1 x i 1 + ω 2 x i 2 + ⋯ + ω n x i n + ε (10)
式中:ω 0 为模型的截距;ω 1 —ωn 为模型的回归系数;ε 为随机误差;yi 为样本i 的目标变量;xi 1 —xin 为样本i 上的不同特征。
y 1 = ω 0 + ω 1 x 11 + ω 2 x 12 + ⋯ + ω n x 1 n + ε 1 y 2 = ω 0 + ω 1 x 21 + ω 2 x 22 + ⋯ + ω n x 2 n + ε 2 ⋮ y m = ω 0 + ω 1 x m 1 + ω 2 x m 2 + ⋯ + ω n x m n + ε m (11)
Y = 1 x 11 ⋯ x 1 n 1 x 21 ⋯ x 2 n ⋮ ⋮ ⋱ ⋮ 1 x m 1 ⋯ x m n ω 0 ω 1 ⋮ ω n + ε 1 ε 2 ⋮ ε m (12)
Y = X ω + ε (13)
式中: Y m 个全部样本回归结果的列向量; X ω ε
3.2 多元线性回归算法
3.2.1 最小二乘法回归算法
最小二乘法(ordinary least squares,OLS)回归是最常见的,也是最简单的回归分析方法。相关回归分析、方差分析和线性模型理论等数理统计学的几大分支都以最小二乘法为理论基础[31 ] 。其基本原则是使所有残差平方和,即样本点与到线性模型超平面的欧氏距离平方和最小。故定义残差平方和为代价函数C (ω ),其表达式为
C ( ω ) = ∑ i = 1 n ( y i - ω 0 - ω 1 x i 1 - ⋯ - ω n x i n ) 2 (14)
最小二乘法多元线性回归的任务,就是找到参数ω 的估计值,使得残差平方和达到最小。根据多元函数求极值原理,在估计值处的代价函数关于回归系数的偏导数应等于0:
∂ C ( ω ) ∂ ω ω = ω ^ = 0 (15)
当( X T X -1 存在时,回归参数的最小二乘估计为
ω ^ = ( X T X ) - 1 X T Y (16)
y ^ = ω ^ 0 + ω ^ 1 x 1 + ω ^ 2 x 2 + ⋯ + ω ^ n x n (17)
3.2.2 OLS回归算法改进
在处理较为复杂数据的回归问题时,OLS线性回归算法通常会出现预测精度不够的问题,导致解得的模型与实际偏差较大。因此,引入复杂度惩罚因子,通过正则项来约束需要优化的参数,从而实现避免过拟合的目的。常用的正则项可以使用L 1范数、L 2范数或将二者结合,3种方法对应的算法分别为Lasso回归,Ridge回归和Elastic Net回归[32 ] ,其代价函数分别为:
C 1 ( ω ) = ∑ i = 1 n ( y i - ω 0 - ω 1 x i 1 - ⋯ - ω n x i n ) 2 + λ ω 1 (18)
C 2 ( ω ) = ∑ i = 1 n ( y i - ω 0 - ω 1 x i 1 - ⋯ - ω n x i n ) 2 + λ ω 2 2 (19)
C 3 ( ω ) = ∑ i = 1 n ( y i - ω 0 - ω 1 x i 1 - ⋯ - ω n x i n ) 2 +
λ ρ ω 1 + λ ( 1 - ρ ) 2 ω 2 2 (20)
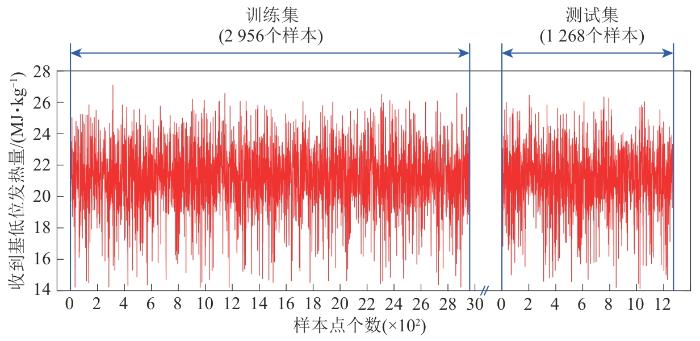
3.3 回归模型建立
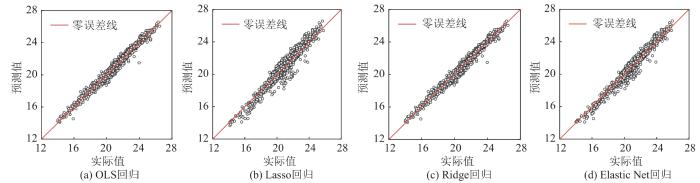
以4 269条数据作为样本,随机选取其中70%的样本作为训练集进行回归拟合,其余的30%作为测试集验证模型准确度,数据集划分情况如图6 所示。然后分别利用OLS回归算法、Lasso回归算法、Ridge回归算法和Elastic Net回归算法对训练集数据进行建模,并在测试集中进行验证。图7 为预测值与实际值的对比图。
图6
图6
数据集的划分
Fig. 6
Division of the data set
图7
图7
发热量实际值与预测值对比
Fig. 7
Comparison between the predicted heat value and actual heat value
为了使对模型泛化能力的评价更加直观可信,本文引入几个常用的统计学评价指标,对不同回归算法的优劣进行量化评价。
常见的回归算法评估指标有平均绝对值误差δ M A E δ R M S E R 2 等。其中,误差指标越小,代表预测值与真实值越接近;决定系数能够度量因变量变异中可由自变量解释部分所占的比例,以此来判断回归模型的解释力,决定系数越大,说明模型的解释力越强。上述评价指标对应的公式如下:
δ M A E = 1 n ∑ i = 1 n y ^ i - y i (21)
δ R M S E = 1 n ∑ i = 1 n ( y ^ i - y i ) 2 (22)
R 2 = 1 - ∑ i = 1 n ( y i - y ^ i ) 2 ∑ i = 1 n ( y i - y ¯ i ) 2 (23)
式中:y ^ i y i y ¯ i n 为测试集样本数量。
由此计算出不同方法对应的评价指标数值,回归方程及评价指标结果如表3 所示。
由表3 可以看出,相较于传统的OLS回归模型,Lasso回归模型和Elastic Net回归模型的平均绝对值误差δ MAE 分别增加了71.472%和32.674%,均方根误差δ RMSE 分别增加了26.172%和10.848%,决定系数R 2 均有一定程度的下降。但采用Ridge回归算法构造回归模型,误差参数有所减小,决定系数也有所提高。
结合图7 来看,采用Ridge回归算法的模型,其测试数据关于零误差线分布更加紧密,说明在4种回归算法中,Ridge回归算法预测效果最优。综上所述,从运行结果上来看,采用Ridge回归算法拟合效果更好。
Ridge回归一种以放弃无偏性、降低精度为代价,以解决病态矩阵问题的回归方法,这种方法在自变量高度相关的情况下有更好的拟合效果。统计学中一般采用方差膨胀系数(variance inflation factor,VIF)来衡量多元线性回归模型中多重共线性的严重程度。方差膨胀系数表示回归系数估计量的方差与假设自变量间不线性相关时方差的比值,其表达式如下:
V I F = 1 1 - R 2 (24)
一般地,当5<VIF<10时,认为模型输入变量有一定多重共线性;当VIF≥10时,认为模型输入变量多重共线性很强。采用Ridge回归模型对M ar ,A ar 以及F C,ar 进行多重共线性分析,结果如表4 所示。
由表4 可知,本文研究模型输入变量间多重共线性较强,与Ridge回归算法的使用场景相符。
综上所述,Ridge回归模型的误差较小,决定系数相对较大;且由于模型自变量之间多重共线性较强,Ridge回归在该情况下对回归方程的拟合有更好的表现效果。综合不同回归模型误差结果对比和Ridge回归算法特性理论推导,确定本文选用Ridge回归算法对煤场数据进行构建多元线性回归模型。
4 K-Means聚类-Ridge回归混合模型
建立K-Means聚类-Ridge回归混合模型,来对分类后的煤种逐一进行回归计算,其流程如图8 所示。
图8
图8
模型的建立流程
Fig. 8
Process of building model
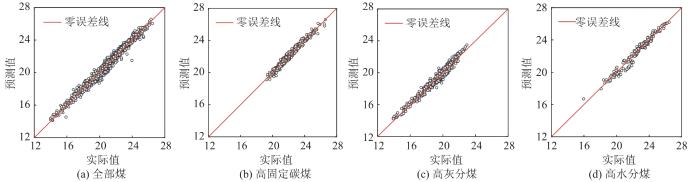
对燃煤数据建立K-Means聚类-Ridge回归混合模型,得到相似煤种各自的回归方程及相关评价指标,如表5 所示。不同煤种预测模型的实际值与预测值对比如图9 所示。由表5 和图9 可以看出,聚类后回归效果较聚类前有明显的改善,其中高固定碳煤最为明显,可将平均绝对值误差降低30.525%,均方根误差降低60.054%,决定系数提高2.320%。
图9
图9
聚类后不同煤种发热量实际值与预测值对比
Fig. 9
Comparison between actual calorific value and predicted calorific value of different coal types after clustering
由上述分析可知,采用K-Means聚类-Ridge回归混合模型能在一定程度上提高根据工业分析预测煤炭发热量的准确度,结果与预期效果一致。
5 结论
1)相较几种实测法测定煤炭发热量,采用建立燃煤线性回归模型的方法可以节省大量的人力与物力,并且可以实现煤炭发热量的在线快速预测。
2)由于煤炭的工业分析数据间有很强的多重共线性,因此相较传统的最小二乘法回归方法以及其他改进方法,Ridge回归方法在煤炭工业分析发热量的预测中有更好的准确性和可信度。
3)与未经聚类的全部煤样对应的回归模型相比,经过K-Means聚类后的煤样预测模型的平均绝对值误差δ MAE 和均方根误差δ RMSE 分别最高减少30.525%和60.054%,决定系数R 2 最高增加2.320%,一定程度上提高了预测的精度。
参考文献
View Option
[2]
王小洋 ,李先国 能源革命背景下我国煤炭运输通道的发展趋势及对策
[J].中国流通经济 ,2019 ,33 (10 ):67 -75 .
[本文引用: 1]
WANG X Y LI X G The development trend of China’s coal transportation in the context of energy revolution and the countermeasures
[J].China Business and Market ,2019 ,33 (10 ):67 -75 .
[本文引用: 1]
[3]
FENG W Z LI L Research and practice on development path of low-carbon,zero-carbon and negative carbon transformation of coal-fired power units under “double carbon” targets
[J].Power Generation Technology ,2022 ,43 (3 ):452 -461 . doi:10.12096/j.2096-4528.pgt.22061
[4]
[本文引用: 1]
ZHANG Q B ZHOU Q F Research on the development path of China’s thermal power generation technology based on the goal of “carbon peak and carbon neutralization”
[J].Power Generation Technology ,2023 ,44 (2 ):143 -154 . doi:10.12096/j.2096-4528.pgt.22092
[本文引用: 1]
[5]
刘志强 ,李建锋 ,潘荔 ,等 中国煤电机组改造升级效果分析与展望
[J].中国电力 ,2024 ,57 (7 ):1 -11 .
[本文引用: 1]
LIU Z Q LI J F PAN L et al Analysis and prospect of transformation and upgrading effects of coal-fired power units in China
[J].Electric Power ,2024 ,57 (7 ):1 -11 .
[本文引用: 1]
[6]
袁翠翠 ,杜政烨 ,茌方 ,等 氧弹热量计性能验收方法实践
[J].煤炭加工与综合利用 ,2022 (3 ):86 -90 .
[本文引用: 1]
YUAN C C DU Z Y CHI F et al Practice of guide for performance acceptance of oxygen bomb calorimeter
[J].Coal Processing & Comprehensive Utilization ,2022 (3 ):86 -90 .
[本文引用: 1]
[7]
张利萍 恒温式热量计测定煤炭发热量的探讨
[J].化工设计通讯 ,2017 ,43 (1 ):145 -147 .
ZHANG L P Discussion on the determination of calorific value of coal by constant temperature calorimeter
[J].Chemical Engineering Design Communications ,2017 ,43 (1 ):145 -147 .
[8]
李莉 ,于磊 ,王超 煤发热量测定方法优化
[J].山东电力技术 ,2015 ,42 (2 ):72 -75 .
[本文引用: 1]
LI L YU L WANG C Optimization of calorific value determination of coal
[J].Shandong Electric Power ,2015 ,42 (2 ):72 -75 .
[本文引用: 1]
[9]
郑忠 ,宋万利 基于主成分分析的中煤发热量的检测研究
[J].煤炭技术 ,2014 ,33 (6 ):218 -220 .
[本文引用: 1]
ZHENG Z SONG W L Detection research of calorific value of middlings based on principal component analysis
[J].Coal Technology ,2014 ,33 (6 ):218 -220 .
[本文引用: 1]
[10]
SONG W HOU Z GU W et al Industrial at-line analysis of coal properties using laser-induced breakdown spectroscopy combined with machine learning
[J].Fuel ,2021 ,306 :121667 . doi:10.1016/j.fuel.2021.121667
[本文引用: 1]
[11]
YAO S QIN H WANG Q et al Optimizing analysis of coal property using laser-induced breakdown and near-infrared reflectance spectroscopies
[J].Spectrochimica Acta Part A:Molecular and Biomolecular Spectroscopy ,2020 ,239 :118492 . doi:10.1016/j.saa.2020.118492
[本文引用: 1]
[12]
谭鹏 ,李鑫 ,张小培 ,等 基于工业分析的煤质发热量预测
[J].煤炭学报 ,2015 ,40 (11 ):2641 -2646 .
[本文引用: 1]
TAN P LI X ZHANG X P et al Prediction of coal heating value based on proximate analysis
[J].Journal of China Coal Society ,2015 ,40 (11 ):2641 -2646 .
[本文引用: 1]
[13]
焦发存 ,刘涛 ,武成利 ,等 淮南矿区煤炭发热量预测模型研究
[J].煤矿机械 ,2022 ,43 (1 ):27 -29 .
[本文引用: 1]
JIAO F C LIU T WU C L et al Study on prediction model of coal calorific value in Huainan mine area
[J].Coal Mine Machinery ,2022 ,43 (1 ):27 -29 .
[本文引用: 1]
[14]
李大虎 ,李秋科 ,王文才 ,等 基于MIV特征选择与PSO-BP神经网络的煤炭发热量预测
[J].煤炭工程 ,2020 ,52 (11 ):154 -160 .
[本文引用: 1]
LI D H LI Q K WANG W C et al Prediction of coal calorific value based on MIV characteristic variable selection and PSO-BP neural network
[J].Coal Engineering ,2020 ,52 (11 ):154 -160 .
[本文引用: 1]
[15]
刘福国 ,刘景龙 ,张绪辉 ,等 基于高斯过程的煤元素分析全成分含量预测研究
[J].中国测试 ,2021 ,47 (8 ):38 -43 .
[本文引用: 1]
LIU F G LIU J L ZHANG X H et al Prediction of comprehensive elemental compositions of coal based on Gaussian process
[J].China Measurement & Test ,2021 ,47 (8 ):38 -43 .
[本文引用: 1]
[16]
赵虹 ,沈利 ,杨建国 ,等 利用煤的工业分析计算元素分析的DE-SVM模型
[J].煤炭学报 ,2010 ,35 (10 ):1721 -1724 .
[本文引用: 1]
ZHAO H SHEN L YANG J G et al The model for calculating ultimate analysis of coal by its proximate analysis based on DE-SVM
[J].Journal of China Coal Society ,2010 ,35 (10 ):1721 -1724 .
[本文引用: 1]
[17]
谢良才 基于BP神经网络的数据挖掘技术探究及其在煤热转化数据规律分析中的应用
[D].西安 :西北大学 ,2021 .
[本文引用: 1]
XIE L C Research on data mining technology based on BP neural network and its application in data law analysis of coal thermal conversion
[D].Xi’an :Northwest University ,2021 .
[本文引用: 1]
[18]
王惠新 ,陈致远 ,王永红 ,等 贵州煤发热量与工业分析指标预测模型
[J].洁净煤技术 ,2020 ,26 (S1 ):112 -115 .
[本文引用: 1]
WANG H X CHEN Z Y WANG Y H et al Prediction model of Guizhou coal calorific value and industrial analysis
[J].Clean Coal Technology ,2020 ,26 (S1 ):112 -115 .
[本文引用: 1]
[19]
樊泉桂 锅炉原理 [M].北京 :中国电力出版社 ,2004 .
[本文引用: 1]
FAN Q G Boiler principle [M].Beijing :China Electric Power Press ,2004 .
[本文引用: 1]
[20]
崔家俊 基于K-means聚类算法的专变用户负荷模式识别方法研究
[D].天津 :河北工业大学 ,2020 .
[本文引用: 1]
CUI J J Research on load pattern recognition method of transformer users based on K-means clustering algorithm
[D].Tianjin :Hebei University of Technology ,2020 .
[本文引用: 1]
[21]
DUBEY A CHOUBEY A A systematic review on k-means clustering techniques
[J].International Journal of Scientific Research Engineering and Technology ,2017 ,6 (6 ):1456 -1475 .
[本文引用: 1]
[22]
XU J LANGE K Power k-means clustering
[C]//International Conference on Machine Learning .Taiyuan,China :IEEE ,2019 :6921 -6931 .
[本文引用: 1]
[23]
SHANG R ARA B , ZADA I et al Analysis of simple K-mean and parallel K-mean clustering for software products and organizational performance using education sector dataset
[J].Scientific Programming ,2021 ,5 :156 -173 . doi:10.1155/2021/9988318
[本文引用: 1]
[26]
DINH D T FUJINAMI T HUYNH V N Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient
[C]//International Symposium on Knowledge and Systems Science .Singapore :Springer ,2019 :1 -17 . doi:10.1007/978-981-15-1209-4_1
[本文引用: 1]
[28]
HASSAN M A S ASSAD U FAROOQ U et al Dynamic price-based demand response through linear regression for microgrids with renewable energy resources
[J].Energies ,2022 ,15 (4 ):1385 -1391 . doi:10.3390/en15041385
[本文引用: 1]
[29]
束洪春 ,代月 ,安娜 ,等 基于线性回归的柔性直流电网纵联保护方法
[J].电工技术学报 ,2022 ,37 (13 ):3213 -3226 .
[本文引用: 1]
SHU H C DAI Y AN N et al Pilot protection method of flexible DC grid based on linear regression
[J].Transactions of China Electrotechnical Society ,2022 ,37 (13 ):3213 -3226 .
[本文引用: 1]
[30]
SARKODIE S A OZTURK I Investigating the environmental Kuznets curve hypothesis in Kenya:a multivariate analysis
[J].Renewable and Sustainable Energy Reviews ,2020 ,117 :109481 . doi:10.1016/j.rser.2019.109481
[本文引用: 1]
[31]
贾小勇 ,徐传胜 ,白欣 最小二乘法的创立及其思想方法
[J].西北大学学报(自然科学版) ,2006 ,36 (3 ):507 -511 .
[本文引用: 1]
JIA X Y XU C S BAI X The invention and way of the thinking on least squares
[J].Journal of Northwestern University (Natural Science Edition) ,2006 ,36 (3 ):507 -511 .
[本文引用: 1]
[32]
RANSTAM J COOK J A LASSO regression
[J].Journal of British Surgery ,2018 ,105 (10 ):1348 -1348 . doi:10.1002/bjs.10895
[本文引用: 1]
中华人民共和国2021年国民经济和社会发展统计公报
1
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
Statistical bulletin on national economic and social development of the People’s Republic of China in 2021
1
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
能源革命背景下我国煤炭运输通道的发展趋势及对策
1
2019
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
The development trend of China’s coal transportation in the context of energy revolution and the countermeasures
1
2019
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
“双碳”目标下煤电机组低碳、零碳和负碳化转型发展路径研究与实践
0
2022
Research and practice on development path of low-carbon,zero-carbon and negative carbon transformation of coal-fired power units under “double carbon” targets
0
2022
基于“双碳”目标的中国火力发电技术发展路径研究
1
2023
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
Research on the development path of China’s thermal power generation technology based on the goal of “carbon peak and carbon neutralization”
1
2023
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
中国煤电机组改造升级效果分析与展望
1
2024
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
Analysis and prospect of transformation and upgrading effects of coal-fired power units in China
1
2024
... 2021年,我国煤炭消费量占能源消费总量的56.0%[1 ] ,鉴于我国富煤、贫油、少气的能源结构,我国以煤炭为主体的能源消费结构在短时间内不会改变[2 -4 ] .随着碳达峰、碳中和目标的提出,促进能源行业向清洁化、低碳化演进已经成为迫切需要解决的问题.综合考虑政策倾向以及我国独特的能源资源禀赋,对传统能源进行技术优化是解决能源行业有序转型问题最经济高效的路径[5 ] .因此,对煤炭特性的分析与研究对我国能源行业的发展具有重要意义. ...
氧弹热量计性能验收方法实践
1
2022
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Practice of guide for performance acceptance of oxygen bomb calorimeter
1
2022
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Discussion on the determination of calorific value of coal by constant temperature calorimeter
0
2017
煤发热量测定方法优化
1
2015
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Optimization of calorific value determination of coal
1
2015
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
基于主成分分析的中煤发热量的检测研究
1
2014
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Detection research of calorific value of middlings based on principal component analysis
1
2014
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Industrial at-line analysis of coal properties using laser-induced breakdown spectroscopy combined with machine learning
1
2021
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
Optimizing analysis of coal property using laser-induced breakdown and near-infrared reflectance spectroscopies
1
2020
... 目前,一般采用实验的方法来测定煤的发热量,包括氧弹热量计法、恒温式热量计法、绝热式热量计法等[6 -8 ] .但由于需要经过严格的程序和专业技术人员的操作,测量周期较长[9 ] ,这就导致测试结果有一定滞后性.近年来,用于煤炭发热量快速测定的瞬发伽马中子活化分析已在实际生产中小范围应用[10 ] ,但这种测试方法存在辐射危害、设备昂贵、运行维护成本高等问题[11 ] . ...
基于工业分析的煤质发热量预测
1
2015
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
Prediction of coal heating value based on proximate analysis
1
2015
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
淮南矿区煤炭发热量预测模型研究
1
2022
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
Study on prediction model of coal calorific value in Huainan mine area
1
2022
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
基于MIV特征选择与PSO-BP神经网络的煤炭发热量预测
1
2020
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
Prediction of coal calorific value based on MIV characteristic variable selection and PSO-BP neural network
1
2020
... 随着计算机技术的发展,许多学者利用机器学习算法对燃煤参数与发热量之间的关系进行了研究,建立了一系列发热量预测模型.谭鹏等[12 ] 建立了非线性支持向量机的煤质发热量预测模型,研究表明,该预测模型比线性模型具备更精准的预测能力.焦发存等[13 ] 建立了基于灰分和固定碳含量的发热量预测模型,以实现对淮南矿区煤炭发热量的快速估算.李大虎等[14 ] 采用最大信息系数特征变量选择与粒子群优化-BP神经网络相结合方法,实现了煤炭发热量非线性预测,总体预测效果较优. ...
基于高斯过程的煤元素分析全成分含量预测研究
1
2021
... 鉴于煤的全元素分析需要专业设备、耗时较长、成本较高[15 ] ,因此多数煤场一般只进行煤的工业分析和硫元素、氢元素分析[16 ] ,这给发热量的预测造成了一定程度的阻碍.煤炭工业分析具有操作简单、成本低廉、响应时间快的特点,本文依据煤种的工业分析数据,利用K-Means聚类算法对全部批次煤炭进行分类,并采用多元线性回归算法,对性质相似的煤种分别建立发热量关于工业分析数据的预测模型,实现对发热量更高精度的预测. ...
Prediction of comprehensive elemental compositions of coal based on Gaussian process
1
2021
... 鉴于煤的全元素分析需要专业设备、耗时较长、成本较高[15 ] ,因此多数煤场一般只进行煤的工业分析和硫元素、氢元素分析[16 ] ,这给发热量的预测造成了一定程度的阻碍.煤炭工业分析具有操作简单、成本低廉、响应时间快的特点,本文依据煤种的工业分析数据,利用K-Means聚类算法对全部批次煤炭进行分类,并采用多元线性回归算法,对性质相似的煤种分别建立发热量关于工业分析数据的预测模型,实现对发热量更高精度的预测. ...
利用煤的工业分析计算元素分析的DE-SVM模型
1
2010
... 鉴于煤的全元素分析需要专业设备、耗时较长、成本较高[15 ] ,因此多数煤场一般只进行煤的工业分析和硫元素、氢元素分析[16 ] ,这给发热量的预测造成了一定程度的阻碍.煤炭工业分析具有操作简单、成本低廉、响应时间快的特点,本文依据煤种的工业分析数据,利用K-Means聚类算法对全部批次煤炭进行分类,并采用多元线性回归算法,对性质相似的煤种分别建立发热量关于工业分析数据的预测模型,实现对发热量更高精度的预测. ...
The model for calculating ultimate analysis of coal by its proximate analysis based on DE-SVM
1
2010
... 鉴于煤的全元素分析需要专业设备、耗时较长、成本较高[15 ] ,因此多数煤场一般只进行煤的工业分析和硫元素、氢元素分析[16 ] ,这给发热量的预测造成了一定程度的阻碍.煤炭工业分析具有操作简单、成本低廉、响应时间快的特点,本文依据煤种的工业分析数据,利用K-Means聚类算法对全部批次煤炭进行分类,并采用多元线性回归算法,对性质相似的煤种分别建立发热量关于工业分析数据的预测模型,实现对发热量更高精度的预测. ...
基于BP神经网络的数据挖掘技术探究及其在煤热转化数据规律分析中的应用
1
2021
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
Research on data mining technology based on BP neural network and its application in data law analysis of coal thermal conversion
1
2021
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
贵州煤发热量与工业分析指标预测模型
1
2020
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
Prediction model of Guizhou coal calorific value and industrial analysis
1
2020
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
1
2004
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
1
2004
... 本文以我国北方某电厂自备煤场为研究对象,该煤场燃煤主要来自太原、阳泉、寿阳、榆林等地.煤场内化学实验室每天对不同批次来煤进行化验,并将化验结果录入到SQL Server数据库中.本文选取近6年的4 269条入场化验信息作为样本,建立工业分析与煤炭发热量的多元线性回归模型.由于工业分析中4个参数总和为100%,所以仅需选取其中3个参数作为输入变量.有研究[17 -18 ] 表明,挥发分含量对发热量影响相对较小,且我国锅炉计算一般采用低位发热量作为衡量指标[19 ] ,故本文选取收到基水分质量分数M ar 、收到基灰分质量分数A ar 以及收到基固定碳质量分数F C,ar 作为输入变量,收到基低位发热量Q net,ar 作为输出变量.经统计,数据集基本情况如表1 所示,全部样本数据的分布情况如图1 所示. ...
基于K-means聚类算法的专变用户负荷模式识别方法研究
1
2020
... 在K-Means聚类算法中,需要采用数据归一化方法减小数据中较大和较小的初始数据所占距离比重对聚类效果的影响,提高模型的收敛速度和计算精度[20 ] .数据归一化是将数据按比例缩放,针对一个数据维度中全部数据范围缩放至[0,1]的操作.由此可以降低由于数据的量纲不同或量级差距大对模型的不良影响.本文采用最大-最小值归一化算法,对数据进行归一化处理,用公式表示其原理如下: ...
Research on load pattern recognition method of transformer users based on K-means clustering algorithm
1
2020
... 在K-Means聚类算法中,需要采用数据归一化方法减小数据中较大和较小的初始数据所占距离比重对聚类效果的影响,提高模型的收敛速度和计算精度[20 ] .数据归一化是将数据按比例缩放,针对一个数据维度中全部数据范围缩放至[0,1]的操作.由此可以降低由于数据的量纲不同或量级差距大对模型的不良影响.本文采用最大-最小值归一化算法,对数据进行归一化处理,用公式表示其原理如下: ...
A systematic review on k-means clustering techniques
1
2017
... K-Means算法是一种源于信号处理的向量量化方法,现在则更多地用在聚类分析中,并广泛应用于数据挖掘领域[21 ] ,是一种经典的分割式分群聚类算法.该算法主要目标是将样本中N 个点按照相似度聚集到k 个聚簇当中,将每个点都分配到离他最近的均值(即聚类中心)对应的聚簇,以之作为聚类的标准.最终,簇内相似度高,簇间相似度低,从而完成聚类. ...
Power k-means clustering
1
2019
... K-Means算法采用了迭代优化的思想,通常被称为劳埃德算法[22 ] .该算法可分为4个步骤: ...
Analysis of simple K-mean and parallel K-mean clustering for software products and organizational performance using education sector dataset
1
2021
... K-Means算法是一种非监督学习算法[23 ] ,聚类不需要对数据进行训练和学习,而是人为规定聚类数,再通过聚类分析将数据聚合成几个群体.不同的聚类数对最终聚类效果有很大的影响,所以需要采用评价指标辅助确定最佳聚类数,以下是评价聚类效果的3种常用方法. ...
Who belongs in the family?
1
1953
... 在聚类分析中,手肘法是一种用于确定数据集中聚类数量的方法,由美国心理测量学家罗伯特⋅拉德⋅桑代克于1953年首次提出[24 ] ,其原理是:设定聚类范围,随着聚类簇数k 的增大,样本划分会更加细致,每个簇的聚合程度会逐渐提高,那么WCSS自然会逐渐变小.当k 值小于最佳聚类簇数时,k 值的不断增大会使每个簇的聚合程度大幅度增加,故WCSS的下降幅度会很大.当k 到达最佳聚类数时,再增加k 所得到的聚合程度会迅速变小,组内平方和的数值变化也趋于平缓.WCSS与k 的关系图是近似于手肘的形状,而这个肘部对应的k 值就是数据的最佳聚类数[25 ] . ...
Clustering by fast search and find of density peaks via HD
1
2016
... 在聚类分析中,手肘法是一种用于确定数据集中聚类数量的方法,由美国心理测量学家罗伯特⋅拉德⋅桑代克于1953年首次提出[24 ] ,其原理是:设定聚类范围,随着聚类簇数k 的增大,样本划分会更加细致,每个簇的聚合程度会逐渐提高,那么WCSS自然会逐渐变小.当k 值小于最佳聚类簇数时,k 值的不断增大会使每个簇的聚合程度大幅度增加,故WCSS的下降幅度会很大.当k 到达最佳聚类数时,再增加k 所得到的聚合程度会迅速变小,组内平方和的数值变化也趋于平缓.WCSS与k 的关系图是近似于手肘的形状,而这个肘部对应的k 值就是数据的最佳聚类数[25 ] . ...
Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient
1
2019
... 在机器学习与数据挖掘领域,轮廓系数法是一种反映数据聚类结果一致性的方法,可以用于评估聚类后簇与簇之间的离散程度[26 ] . ...
A dendrite method for cluster analysis
1
1974
... 卡林斯基-哈拉巴斯(Calinski-Harabasz,CH)指数是由Calinski和Harabasz于1974年引入的一种可用于在非监督学习中评估聚类模型的指标[27 ] .CH指数(也称为方差比标准)通过计算所有集群的集群间离散度总和与集群内离散度总和的比率来对聚类效果进行评价,其定义如下: ...
Dynamic price-based demand response through linear regression for microgrids with renewable energy resources
1
2022
... 回归是监督学习的一个典型问题,可以用于预测输入变量和输出变量之间的关系[28 ] .输出变量的值随输入变量值的变化而变化,回归模型正是表示从输入变量到输出变量映射的函数. ...
基于线性回归的柔性直流电网纵联保护方法
1
2022
... 在统计学中,线性回归是利用线性回归方程的最小平方函数对一个或多个自变量(输入变量)和因变量(输出变量)之间关系进行建模的一种回归分析[29 ] .其中,大于一个自变量情况的叫作多元线性回归分析[30 ] ,其基本原理如下: ...
Pilot protection method of flexible DC grid based on linear regression
1
2022
... 在统计学中,线性回归是利用线性回归方程的最小平方函数对一个或多个自变量(输入变量)和因变量(输出变量)之间关系进行建模的一种回归分析[29 ] .其中,大于一个自变量情况的叫作多元线性回归分析[30 ] ,其基本原理如下: ...
Investigating the environmental Kuznets curve hypothesis in Kenya:a multivariate analysis
1
2020
... 在统计学中,线性回归是利用线性回归方程的最小平方函数对一个或多个自变量(输入变量)和因变量(输出变量)之间关系进行建模的一种回归分析[29 ] .其中,大于一个自变量情况的叫作多元线性回归分析[30 ] ,其基本原理如下: ...
最小二乘法的创立及其思想方法
1
2006
... 最小二乘法(ordinary least squares,OLS)回归是最常见的,也是最简单的回归分析方法.相关回归分析、方差分析和线性模型理论等数理统计学的几大分支都以最小二乘法为理论基础[31 ] .其基本原则是使所有残差平方和,即样本点与到线性模型超平面的欧氏距离平方和最小.故定义残差平方和为代价函数C (ω ),其表达式为 ...
The invention and way of the thinking on least squares
1
2006
... 最小二乘法(ordinary least squares,OLS)回归是最常见的,也是最简单的回归分析方法.相关回归分析、方差分析和线性模型理论等数理统计学的几大分支都以最小二乘法为理论基础[31 ] .其基本原则是使所有残差平方和,即样本点与到线性模型超平面的欧氏距离平方和最小.故定义残差平方和为代价函数C (ω ),其表达式为 ...
LASSO regression
1
2018
... 在处理较为复杂数据的回归问题时,OLS线性回归算法通常会出现预测精度不够的问题,导致解得的模型与实际偏差较大.因此,引入复杂度惩罚因子,通过正则项来约束需要优化的参数,从而实现避免过拟合的目的.常用的正则项可以使用L 1范数、L 2范数或将二者结合,3种方法对应的算法分别为Lasso回归,Ridge回归和Elastic Net回归[32 ] ,其代价函数分别为: ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}