新型电力系统发展蓝皮书
1
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
Blue book of new power system development
1
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
新型电力系统背景下电网发展业务数字化转型架构及路径研究
1
2022
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
Research on digital transformation architecture and path of power grid development planning business under new power system blueprint
1
2022
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
城市电网本地通信网络数字化感知业务与通信技术适配研究
1
2023
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
Adaptation of digital perception service and communication technologies for local communication network of urban grid
1
2023
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
中国三代核电经济评价方法与参数优化
1
2024
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
Economic evaluation method and parameter optimization for ThirdGeneration nuclear power in China
1
2024
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
电力系统多应用场景统一平台的研究与建设
1
2024
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
Development and construction of multi-scenario-integrated platform for power systems
1
2024
... 国家能源局在新型核电系统数字技术支撑体系白皮书中指出,为保障能源核电安全可靠供应、加快清洁低碳转型,并助力实现“双碳”目标的重大战略任务,必须要构建新型核电系统[1].这要求数字技术与实体电网深度融合,提高电网数字化水平[2-3].随着核电工业的快速发展,我国的核电系统遇到了新的挑战,如核电能源结构多样化、核电负荷持续增长及其不确定性、核电市场化改革以及核电跨区域传输等[4].此外,随着时间的推移和核电智能终端的不断升级,核电数据的收集、处理难度和复杂性也在不断增加.因此,如何利用高效的信息化手段为日益复杂的核电系统提供卓越的信息处理能力显得尤为重要[5]. ...
大语言模型增强的知识图谱问答研究进展综述
1
2024
... 大语言模型(large language model,LLM)的出现为核电领域带来了前所未有的发展机遇.大语言模型是一种基于深度学习的自然语言处理技术,凭借其海量的训练数据,能够捕捉词语之间的复杂关系,解析上下文语义,从而在专业对话、翻译、文本生成等任务中表现出高度的智能化水平[6].目前,大语言模型已在医疗、法律、金融、科技等多个专业领域得到了广泛的研究与应用,并取得了显著的成果.在核电领域中,大语言模型的应用潜力同样巨大,可以用于负荷预测、智能问答、故障检测、决策支持等多个方面,提升系统的智能化水平和运营效率.这不仅可以提高核电系统的可靠性,还可为可再生能源整合和智能电网的发展提供有力支持. ...
Overview of knowledge graph question answering enhanced by large language models
1
2024
... 大语言模型(large language model,LLM)的出现为核电领域带来了前所未有的发展机遇.大语言模型是一种基于深度学习的自然语言处理技术,凭借其海量的训练数据,能够捕捉词语之间的复杂关系,解析上下文语义,从而在专业对话、翻译、文本生成等任务中表现出高度的智能化水平[6].目前,大语言模型已在医疗、法律、金融、科技等多个专业领域得到了广泛的研究与应用,并取得了显著的成果.在核电领域中,大语言模型的应用潜力同样巨大,可以用于负荷预测、智能问答、故障检测、决策支持等多个方面,提升系统的智能化水平和运营效率.这不仅可以提高核电系统的可靠性,还可为可再生能源整合和智能电网的发展提供有力支持. ...
人工智能引领未来:大语言模型在电力系统中的创新应用
1
2023
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
Artificial intelligence leads the future:innovative applications of big language modeling in power systems
1
2023
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
Survey of hallucination in natural language generation
1
2023
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
基于BERT模型的主设备缺陷诊断方法研究
1
2025
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
Research on primary equipment defect diagnosis method based on the BERT model
1
2025
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
知识图谱及其在电力系统中的应用研究综述
1
2020
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
Review on knowledge graph and its application in power systems
1
2020
... 大语言模型在核电领域的发展虽然前景广阔,但仍面临一些严峻的挑战.首先,知识局限性是一个重要问题.大语言模型在训练过程中只能从其训练数据中获取知识,这意味着大语言模型的回复受到训练数据时间点的限制,无法动态更新以反映最新的信息.在核电领域,尤其需要模型能够利用最新的政策文件和技术进展进行推理,如对于最新发布的核电政策和标准[7],大语言模型很难根据自身内部存储的知识来进行回答.其次,幻觉(hallucination)问题也是大语言模型的一大短板[8-9].纯生成式模型在缺乏外部知识支持的情况下,容易出现幻觉,即生成的内容可能与现实情况不符,甚至完全没有依据[10].这种情况在核电领域尤其不可接受,因为该领域对信息的准确性和可靠性要求极高,任何错误的信息都可能导致严重的后果.最后,大语言模型的推理开销同样不容忽视.纯生成式模型在进行推理时计算成本较高,特别是在处理长文本或需要深度推理的复杂任务时,其生成效率会显著下降.这不仅增加了使用成本,也限制了其在大规模应用场景中的可行性. ...
Retrieval-augmented generation for AI-generated content:a survey
1
... 为了解决上述问题,检索增强生成(retrieval-augmented generation,RAG)技术应运而生,成为大语言模型时代的重要应用范式.RAG的核心思想是在大语言模型生成答案之前,从广泛的文档数据库中检索出相关信息,为大语言模型提供丰富的背景知识,使得生成的内容更加准确和相关.RAG技术结合检索和生成2个步骤,通过引入真实、可靠的文献资料,有效地缓解了语言模型常见的幻觉问题[11].此外,RAG还可以直接检索最新的文档材料,加快知识更新的速度,使得语言模型能更及时地反映最新的信息和研究成果.更重要的是,RAG增强了生成内容的可追溯性,用户可以掌握生成内容的来源,从而提高了对模型输出的信任度.这种透明性在核电领域的许多实际应用场景中尤为重要,如智能问答、辅助决策和故障诊断等,这是因为在这些场景中用户对信息的准确性和可靠性有着更高的要求. ...
基于大语言模型的低碳电力市场发展应用前景
1
2024
... 作为重要研究方向之一,语言模型经历了从早期的统计和神经语言模型到基于Transformer的预训练模型的发展.近年来,研究发现,随着预训练语言模型参数和数据量的增加,大语言模型(如GPT-3、PaLM、LLaMA等)在效果上显著提升,并展现出小模型所不具备的特殊能力,如上下文学习和逐步推理[12].代表性的大语言模型ChatGPT展示了出色的人机对话和任务解决能力,对人工智能(artificial intelligence,AI)的研究产生了重大影响[13]. ...
Prospects for development of low-carbon electricity markets based on large language models
1
2024
... 作为重要研究方向之一,语言模型经历了从早期的统计和神经语言模型到基于Transformer的预训练模型的发展.近年来,研究发现,随着预训练语言模型参数和数据量的增加,大语言模型(如GPT-3、PaLM、LLaMA等)在效果上显著提升,并展现出小模型所不具备的特殊能力,如上下文学习和逐步推理[12].代表性的大语言模型ChatGPT展示了出色的人机对话和任务解决能力,对人工智能(artificial intelligence,AI)的研究产生了重大影响[13]. ...
Openagi:when LLM meets domain experts
1
2023
... 作为重要研究方向之一,语言模型经历了从早期的统计和神经语言模型到基于Transformer的预训练模型的发展.近年来,研究发现,随着预训练语言模型参数和数据量的增加,大语言模型(如GPT-3、PaLM、LLaMA等)在效果上显著提升,并展现出小模型所不具备的特殊能力,如上下文学习和逐步推理[12].代表性的大语言模型ChatGPT展示了出色的人机对话和任务解决能力,对人工智能(artificial intelligence,AI)的研究产生了重大影响[13]. ...
基于大语言模型的新型电力系统生成式智能应用模式初探
1
2024
... 目前,核电领域的大语言模型实现方案主要有2种.第一种是通过有监督微调的方法,对现有的通用大语言模型进行核电领域数据的特定训练,以适配核电领域特点.这一方案的实施过程相对简单,只需收集核电领域的数据并设计特定的任务指令格式,然后将数据输入大语言模型进行训练.这种有监督微调的方法在一定程度上能够提升模型处理复杂任务的能力.然而,该方法的结果并不总是可靠,最终得到的模型仍然是一个黑箱,缺乏安全性和可解释性.因此,对于核电领域那些需要可解释性和安全性的应用,有监督微调的方法效果往往难以保证[14]. ...
Exploration of generative intelligent application mode for new power systems based on large language models
1
2024
... 目前,核电领域的大语言模型实现方案主要有2种.第一种是通过有监督微调的方法,对现有的通用大语言模型进行核电领域数据的特定训练,以适配核电领域特点.这一方案的实施过程相对简单,只需收集核电领域的数据并设计特定的任务指令格式,然后将数据输入大语言模型进行训练.这种有监督微调的方法在一定程度上能够提升模型处理复杂任务的能力.然而,该方法的结果并不总是可靠,最终得到的模型仍然是一个黑箱,缺乏安全性和可解释性.因此,对于核电领域那些需要可解释性和安全性的应用,有监督微调的方法效果往往难以保证[14]. ...
基于知识图谱的输变电工程辅助评审系统架构及关键技术分析
1
2023
... 知识图谱是以图的形式表现客观世界中实体及其相互关系的结构化语义知识库[15].一般在知识图谱中,实体间关系的基本组成单位为“实体-关系-实体”三元组,实体的属性特征则使用“属性-值”对来表示.在知识图谱中,“实体”是知识图谱的基本元素,“关系”是不同实体之间的关系,“属性”是对实体的说明,“值”是实体属性的具体数值.在知识图谱中,通过上述的“实体-关系-实体”方式相互连接,形成网状的知识结构,即可构成客观世界中知识的符号化表达方式[16].知识图谱按内容进行分类,主要分为2种:一种是通用的知识图谱,它涵盖了泛用领域的知识,适用于多种应用场景;另一种是领域知识图谱,这类知识图谱专注于特定领域的知识,更加专业,适用于领域专家或特定场景.核电系统知识图谱是将知识图谱技术应用于核电系统领域的技术形式,属于领域知识图谱[17]. ...
Architecture and key technology analysis of power transmission and transformation engineering auxiliary recheck system based on knowledge graph
1
2023
... 知识图谱是以图的形式表现客观世界中实体及其相互关系的结构化语义知识库[15].一般在知识图谱中,实体间关系的基本组成单位为“实体-关系-实体”三元组,实体的属性特征则使用“属性-值”对来表示.在知识图谱中,“实体”是知识图谱的基本元素,“关系”是不同实体之间的关系,“属性”是对实体的说明,“值”是实体属性的具体数值.在知识图谱中,通过上述的“实体-关系-实体”方式相互连接,形成网状的知识结构,即可构成客观世界中知识的符号化表达方式[16].知识图谱按内容进行分类,主要分为2种:一种是通用的知识图谱,它涵盖了泛用领域的知识,适用于多种应用场景;另一种是领域知识图谱,这类知识图谱专注于特定领域的知识,更加专业,适用于领域专家或特定场景.核电系统知识图谱是将知识图谱技术应用于核电系统领域的技术形式,属于领域知识图谱[17]. ...
A review:knowledge reasoning over knowledge graph
2
2020
... 知识图谱是以图的形式表现客观世界中实体及其相互关系的结构化语义知识库[15].一般在知识图谱中,实体间关系的基本组成单位为“实体-关系-实体”三元组,实体的属性特征则使用“属性-值”对来表示.在知识图谱中,“实体”是知识图谱的基本元素,“关系”是不同实体之间的关系,“属性”是对实体的说明,“值”是实体属性的具体数值.在知识图谱中,通过上述的“实体-关系-实体”方式相互连接,形成网状的知识结构,即可构成客观世界中知识的符号化表达方式[16].知识图谱按内容进行分类,主要分为2种:一种是通用的知识图谱,它涵盖了泛用领域的知识,适用于多种应用场景;另一种是领域知识图谱,这类知识图谱专注于特定领域的知识,更加专业,适用于领域专家或特定场景.核电系统知识图谱是将知识图谱技术应用于核电系统领域的技术形式,属于领域知识图谱[17]. ...
... 因此,GRAG技术被提出,大语言模型可以从知识图谱等图结构中检索、提取出高质量的知识内容,增强输出的准确性和严谨性.与传统的RAG技术相比,GRAG技术主要有以下优势[16]: ...
电力数据的知识图谱构建及典型应用
1
2024
... 知识图谱是以图的形式表现客观世界中实体及其相互关系的结构化语义知识库[15].一般在知识图谱中,实体间关系的基本组成单位为“实体-关系-实体”三元组,实体的属性特征则使用“属性-值”对来表示.在知识图谱中,“实体”是知识图谱的基本元素,“关系”是不同实体之间的关系,“属性”是对实体的说明,“值”是实体属性的具体数值.在知识图谱中,通过上述的“实体-关系-实体”方式相互连接,形成网状的知识结构,即可构成客观世界中知识的符号化表达方式[16].知识图谱按内容进行分类,主要分为2种:一种是通用的知识图谱,它涵盖了泛用领域的知识,适用于多种应用场景;另一种是领域知识图谱,这类知识图谱专注于特定领域的知识,更加专业,适用于领域专家或特定场景.核电系统知识图谱是将知识图谱技术应用于核电系统领域的技术形式,属于领域知识图谱[17]. ...
Construction of knowledge map of power data and its typical application
1
2024
... 知识图谱是以图的形式表现客观世界中实体及其相互关系的结构化语义知识库[15].一般在知识图谱中,实体间关系的基本组成单位为“实体-关系-实体”三元组,实体的属性特征则使用“属性-值”对来表示.在知识图谱中,“实体”是知识图谱的基本元素,“关系”是不同实体之间的关系,“属性”是对实体的说明,“值”是实体属性的具体数值.在知识图谱中,通过上述的“实体-关系-实体”方式相互连接,形成网状的知识结构,即可构成客观世界中知识的符号化表达方式[16].知识图谱按内容进行分类,主要分为2种:一种是通用的知识图谱,它涵盖了泛用领域的知识,适用于多种应用场景;另一种是领域知识图谱,这类知识图谱专注于特定领域的知识,更加专业,适用于领域专家或特定场景.核电系统知识图谱是将知识图谱技术应用于核电系统领域的技术形式,属于领域知识图谱[17]. ...
知识图谱数据管理研究综述
1
2019
... 在核电领域知识图谱构建技术方面,许多专家学者进行了深入研究,如:王鑫等[18]采用层次学习和事实学习的方法,成功实现了自底向上的知识图谱构建,这种方式不仅提高了构建效率,也增强了图谱的可解释性;刘津等[19]则结合领域专家的丰富经验,开展了自顶向下与自底向上的中文专业词典和知识图谱构建,进一步推动了专业领域知识的系统化和结构化. ...
Research on knowledge graph data management:a survey
1
2019
... 在核电领域知识图谱构建技术方面,许多专家学者进行了深入研究,如:王鑫等[18]采用层次学习和事实学习的方法,成功实现了自底向上的知识图谱构建,这种方式不仅提高了构建效率,也增强了图谱的可解释性;刘津等[19]则结合领域专家的丰富经验,开展了自顶向下与自底向上的中文专业词典和知识图谱构建,进一步推动了专业领域知识的系统化和结构化. ...
知识图谱在电力领域的应用与研究
1
2020
... 在核电领域知识图谱构建技术方面,许多专家学者进行了深入研究,如:王鑫等[18]采用层次学习和事实学习的方法,成功实现了自底向上的知识图谱构建,这种方式不仅提高了构建效率,也增强了图谱的可解释性;刘津等[19]则结合领域专家的丰富经验,开展了自顶向下与自底向上的中文专业词典和知识图谱构建,进一步推动了专业领域知识的系统化和结构化. ...
Application and research of knowledge graph in electric power field
1
2020
... 在核电领域知识图谱构建技术方面,许多专家学者进行了深入研究,如:王鑫等[18]采用层次学习和事实学习的方法,成功实现了自底向上的知识图谱构建,这种方式不仅提高了构建效率,也增强了图谱的可解释性;刘津等[19]则结合领域专家的丰富经验,开展了自顶向下与自底向上的中文专业词典和知识图谱构建,进一步推动了专业领域知识的系统化和结构化. ...
基于知识图谱与大语言模型的电力行业知识检索分析系统研发与应用
1
2024
... 通过引入大语言模型,可以实现知识图谱与自然语言处理技术的充分协作与互补[20].大语言模型具备强大的理解和生成能力,可以帮助用户更轻松地访问和利用知识图谱中的信息,提升知识图谱的实际应用效果[21].大语言模型和知识图谱对比如表1所示,结合这2种技术,有望克服当前知识图谱面临的问题,推动领域知识的进一步发展与应用. ...
Development and application of a knowledge retrieval and analysis system for the power industry based on knowledge graph and large language model
1
2024
... 通过引入大语言模型,可以实现知识图谱与自然语言处理技术的充分协作与互补[20].大语言模型具备强大的理解和生成能力,可以帮助用户更轻松地访问和利用知识图谱中的信息,提升知识图谱的实际应用效果[21].大语言模型和知识图谱对比如表1所示,结合这2种技术,有望克服当前知识图谱面临的问题,推动领域知识的进一步发展与应用. ...
Graph retrieval-augmented generation:a survey
2
... 通过引入大语言模型,可以实现知识图谱与自然语言处理技术的充分协作与互补[20].大语言模型具备强大的理解和生成能力,可以帮助用户更轻松地访问和利用知识图谱中的信息,提升知识图谱的实际应用效果[21].大语言模型和知识图谱对比如表1所示,结合这2种技术,有望克服当前知识图谱面临的问题,推动领域知识的进一步发展与应用. ...
... 然而,依托知识库构建的问答系统处理复杂问题的能力仍然有限.大语言模型的引入为问答系统赋予了更强的智能推理和分析能力,使其能够解决更为复杂的问题.尽管如此,这些大语言模型在实际应用中常常面临幻觉问题,导致问答系统的可信度下降.为了解决这一问题,可以结合知识图谱,利用GRAG来增强问答系统的可解释性,从而提高其在回答核电领域专业知识问题的准确性[21].每次输入用户查询时,大语言模型都可以先通过GRAG从知识图谱中检索出高质量的内容,然后凭借自身强大推理能力来快速响应用户的查询,并且提供更为可靠的答案. ...
Unifying large language models and knowledge graphs:a roadmap
1
2024
... 与传统基于图神经网络(graph neural network,GNN)的检索方法相比,GRAG技术在核电领域的应用具有更大优势.基于GNN的检索方法通常依赖于节点和边的嵌入表示,虽然能够捕捉局部图结构信息,但在处理大规模知识图谱时,计算复杂度较高且难以处理复杂的语义关系.而GRAG技术通过大语言模型的强大语义理解能力和知识图谱的结构化信息,能够在更广泛的语义空间中进行检索和推理,同时保持较高的效率和准确性[22]. ...
基于大语言模型的电力系统通用人工智能展望:理论与应用
1
2024
... 核电风险评估是核能领域的重要基础工作,其基于历史和实时的安全数据、设备状态、环境变化、维护记录等信息,预测未来一段时间内核电站的潜在风险需求[23].核电风险评估是确保核电系统安全、经济、高效运行的关键工具,直接影响着核反应堆的运行、冷却系统的稳定、应急响应以及核能市场的各个环节. ...
Prospect of artificial general intelligence for power systems based on large language model:theory and applications
1
2024
... 核电风险评估是核能领域的重要基础工作,其基于历史和实时的安全数据、设备状态、环境变化、维护记录等信息,预测未来一段时间内核电站的潜在风险需求[23].核电风险评估是确保核电系统安全、经济、高效运行的关键工具,直接影响着核反应堆的运行、冷却系统的稳定、应急响应以及核能市场的各个环节. ...
Distribution of residual autocorrelations in autoregressive-integrated moving average time series models
1
1970
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
Time series analysis and forecasting of coronavirus disease in Indonesia using ARIMA model and PROPHET
1
2021
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
变电设备温度态势感知及辅助决策系统方案研究
1
2024
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
Research on temperature situation awareness and auxiliary decision-making system scheme of substation equipment
1
2024
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
基于DWT-Informer的台区短期负荷预测
1
2024
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
Short-term substation load forecasting based on DWT-Informer model
1
2024
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
考虑强对流天气的乡镇配电网树线矛盾风险预警及优化处理
1
2023
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
Risk warning and optimization processing for tree-line contradiction in rural distribution network considering severe convective weather
1
2023
... 目前,核电风险评估方法主要分为传统统计方法和机器学习方法两大类.典型的统计方法有自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[24]和Prophet[25]等,其中:ARIMA通过差分将非平稳时间序列转化为平稳时间序列,非常适合短期风险评估[26];Prophet则适合包含环境因素和设备维护周期的风险评估[27].然而,传统方法在应对核电风险评估中的非线性问题时存在局限性,尤其是在面对高维度数据时,往往无法取得理想效果.因此,越来越多的研究者开始探索机器学习方法,尤其是支持向量机(supported vector machine,SVM)等先进算法[28].这些方法利用非线性核函数建模,能够捕捉复杂的风险数据关系,适合中长期风险评估. ...
Time-LLM:time series forecasting by reprogramming large language models
1
... 相比于传统统计方法和机器学习方法,采用大语言模型进行核电风险预测,能够更好地捕捉复杂高维时间序列中的非线性关系.大语言模型的优势在于其无需进行大量包括特征工程在内的复杂建模,能够自动从数据中提取关键特征,从而提高预测的准确性[29].此外,大语言模型还可以利用自身的上下文学习能力,结合GRAG外部提供的时间、空间、社会经济等因素,深入揭示不同数据之间的隐含关联,进一步提升负荷预测的精度. ...
A Survey on complex knowledge base question answering: methods, challenges and solutions
1
... 传统的智能问答系统主要依赖知识库匹配来实现,按工作原理通常分为基于语义分析的系统和信息检索的系统2类[30].这些系统在处理简单问题时表现良好,但在面对复杂的查询时,往往效果不佳.为了解决该问题,深度学习的方法被应用于智能问答系统中.文献[31]总结了在问答系统实现中使用Transformer模型的相关研究.文献[32]则通过构建核电领域知识图谱来实现智能搜索、问答和推荐,将问题转化为对知识图谱进行查询并返回答案. ...
Transformer models used for text-based question answering systems
1
2023
... 传统的智能问答系统主要依赖知识库匹配来实现,按工作原理通常分为基于语义分析的系统和信息检索的系统2类[30].这些系统在处理简单问题时表现良好,但在面对复杂的查询时,往往效果不佳.为了解决该问题,深度学习的方法被应用于智能问答系统中.文献[31]总结了在问答系统实现中使用Transformer模型的相关研究.文献[32]则通过构建核电领域知识图谱来实现智能搜索、问答和推荐,将问题转化为对知识图谱进行查询并返回答案. ...
电力领域知识图谱的构建与应用
1
2021
... 传统的智能问答系统主要依赖知识库匹配来实现,按工作原理通常分为基于语义分析的系统和信息检索的系统2类[30].这些系统在处理简单问题时表现良好,但在面对复杂的查询时,往往效果不佳.为了解决该问题,深度学习的方法被应用于智能问答系统中.文献[31]总结了在问答系统实现中使用Transformer模型的相关研究.文献[32]则通过构建核电领域知识图谱来实现智能搜索、问答和推荐,将问题转化为对知识图谱进行查询并返回答案. ...
Construction and application of knowledge graph in the electric power field
1
2021
... 传统的智能问答系统主要依赖知识库匹配来实现,按工作原理通常分为基于语义分析的系统和信息检索的系统2类[30].这些系统在处理简单问题时表现良好,但在面对复杂的查询时,往往效果不佳.为了解决该问题,深度学习的方法被应用于智能问答系统中.文献[31]总结了在问答系统实现中使用Transformer模型的相关研究.文献[32]则通过构建核电领域知识图谱来实现智能搜索、问答和推荐,将问题转化为对知识图谱进行查询并返回答案. ...
基于知识图谱的煤矿建设安全领域知识管理研究
1
2024
... 在核电系统的建设过程中,随着数据的不断积累,知识逐渐呈现出冗余的趋势.这种冗余不仅影响信息的有效利用,还可能导致决策过程中的误判.因此,迫切需要一种系统化的方法来存储和管理技术文档、研究成果以及行业经验,以此来提高知识的共享性和决策的有效性.当前,知识管理和决策支持的方法主要依赖于知识图谱.文献[33]探究了知识图谱在安全领域的知识管理应用,提出了构建领域知识图谱的4个阶段.文献[34]提出了利用电力行业内部专业数据与外部客服语料数据构建知识图谱的应用框架,通过问答系统的形式为用户提供决策支持. ...
Research on knowledge management in coal mine construction safety field based on knowledge graph
1
2024
... 在核电系统的建设过程中,随着数据的不断积累,知识逐渐呈现出冗余的趋势.这种冗余不仅影响信息的有效利用,还可能导致决策过程中的误判.因此,迫切需要一种系统化的方法来存储和管理技术文档、研究成果以及行业经验,以此来提高知识的共享性和决策的有效性.当前,知识管理和决策支持的方法主要依赖于知识图谱.文献[33]探究了知识图谱在安全领域的知识管理应用,提出了构建领域知识图谱的4个阶段.文献[34]提出了利用电力行业内部专业数据与外部客服语料数据构建知识图谱的应用框架,通过问答系统的形式为用户提供决策支持. ...
基于知识图谱的电力标准智能问答系统研究
1
2024
... 在核电系统的建设过程中,随着数据的不断积累,知识逐渐呈现出冗余的趋势.这种冗余不仅影响信息的有效利用,还可能导致决策过程中的误判.因此,迫切需要一种系统化的方法来存储和管理技术文档、研究成果以及行业经验,以此来提高知识的共享性和决策的有效性.当前,知识管理和决策支持的方法主要依赖于知识图谱.文献[33]探究了知识图谱在安全领域的知识管理应用,提出了构建领域知识图谱的4个阶段.文献[34]提出了利用电力行业内部专业数据与外部客服语料数据构建知识图谱的应用框架,通过问答系统的形式为用户提供决策支持. ...
Knowledge graph-based intelligent Q & A system for power standards
1
2024
... 在核电系统的建设过程中,随着数据的不断积累,知识逐渐呈现出冗余的趋势.这种冗余不仅影响信息的有效利用,还可能导致决策过程中的误判.因此,迫切需要一种系统化的方法来存储和管理技术文档、研究成果以及行业经验,以此来提高知识的共享性和决策的有效性.当前,知识管理和决策支持的方法主要依赖于知识图谱.文献[33]探究了知识图谱在安全领域的知识管理应用,提出了构建领域知识图谱的4个阶段.文献[34]提出了利用电力行业内部专业数据与外部客服语料数据构建知识图谱的应用框架,通过问答系统的形式为用户提供决策支持. ...
Matrix profile XXIV:scaling time series anomaly detection to trillions of datapoints and ultra-fast arriving data streams
1
2022
... 为保障核电系统的稳定运行,及时准确的故障诊断机制至关重要,它不仅能够降低故障引发的影响和损害,还能有效延长设备的使用寿命.在核电系统中,通常会对设备产生的时序数据进行深入挖掘,以推测可能发生的故障,如:文献[35]通过识别时序数据中的异常片段挖掘发生故障的原因;文献[36]通过从设备故障诊断数据中提取有用知识来构建知识图谱,实现快速故障诊断;文献[37]提出基于图神经网络构建电力缺陷诊断文本评级的分类方法,同时结合大语言模型实现故障智能诊断分析. ...
知识图谱在装备故障诊断领域的研究与应用综述
1
2024
... 为保障核电系统的稳定运行,及时准确的故障诊断机制至关重要,它不仅能够降低故障引发的影响和损害,还能有效延长设备的使用寿命.在核电系统中,通常会对设备产生的时序数据进行深入挖掘,以推测可能发生的故障,如:文献[35]通过识别时序数据中的异常片段挖掘发生故障的原因;文献[36]通过从设备故障诊断数据中提取有用知识来构建知识图谱,实现快速故障诊断;文献[37]提出基于图神经网络构建电力缺陷诊断文本评级的分类方法,同时结合大语言模型实现故障智能诊断分析. ...
Overview of research and application of knowledge graph in equipment fault diagnosis
1
2024
... 为保障核电系统的稳定运行,及时准确的故障诊断机制至关重要,它不仅能够降低故障引发的影响和损害,还能有效延长设备的使用寿命.在核电系统中,通常会对设备产生的时序数据进行深入挖掘,以推测可能发生的故障,如:文献[35]通过识别时序数据中的异常片段挖掘发生故障的原因;文献[36]通过从设备故障诊断数据中提取有用知识来构建知识图谱,实现快速故障诊断;文献[37]提出基于图神经网络构建电力缺陷诊断文本评级的分类方法,同时结合大语言模型实现故障智能诊断分析. ...
融合大模型与图神经网络的电力设备缺陷诊断
1
2024
... 为保障核电系统的稳定运行,及时准确的故障诊断机制至关重要,它不仅能够降低故障引发的影响和损害,还能有效延长设备的使用寿命.在核电系统中,通常会对设备产生的时序数据进行深入挖掘,以推测可能发生的故障,如:文献[35]通过识别时序数据中的异常片段挖掘发生故障的原因;文献[36]通过从设备故障诊断数据中提取有用知识来构建知识图谱,实现快速故障诊断;文献[37]提出基于图神经网络构建电力缺陷诊断文本评级的分类方法,同时结合大语言模型实现故障智能诊断分析. ...
Diagnosis of power system defects by large language models and graph neural networks
1
2024
... 为保障核电系统的稳定运行,及时准确的故障诊断机制至关重要,它不仅能够降低故障引发的影响和损害,还能有效延长设备的使用寿命.在核电系统中,通常会对设备产生的时序数据进行深入挖掘,以推测可能发生的故障,如:文献[35]通过识别时序数据中的异常片段挖掘发生故障的原因;文献[36]通过从设备故障诊断数据中提取有用知识来构建知识图谱,实现快速故障诊断;文献[37]提出基于图神经网络构建电力缺陷诊断文本评级的分类方法,同时结合大语言模型实现故障智能诊断分析. ...
Emergent abilities of large language models
1
... 在大语言模型中,通常模型参数量是非常重要的指标,它体现了模型的表达能力、泛化能力及处理能力.随着模型参数的增加,大语言模型逐步涌现出了各种功能[38].代表性的大语言模型包括闭源的GPT-4[39]及开源可部署的LLaMa-3[40]、Qwen2[41]等. ...
GPT-4 technical report
1
... 在大语言模型中,通常模型参数量是非常重要的指标,它体现了模型的表达能力、泛化能力及处理能力.随着模型参数的增加,大语言模型逐步涌现出了各种功能[38].代表性的大语言模型包括闭源的GPT-4[39]及开源可部署的LLaMa-3[40]、Qwen2[41]等. ...
The llama 3 herd of models
1
... 在大语言模型中,通常模型参数量是非常重要的指标,它体现了模型的表达能力、泛化能力及处理能力.随着模型参数的增加,大语言模型逐步涌现出了各种功能[38].代表性的大语言模型包括闭源的GPT-4[39]及开源可部署的LLaMa-3[40]、Qwen2[41]等. ...
Qwen2 technical report
1
... 在大语言模型中,通常模型参数量是非常重要的指标,它体现了模型的表达能力、泛化能力及处理能力.随着模型参数的增加,大语言模型逐步涌现出了各种功能[38].代表性的大语言模型包括闭源的GPT-4[39]及开源可部署的LLaMa-3[40]、Qwen2[41]等. ...
MiniCPM-V:a GPT-4V level MLLM on your phone
1
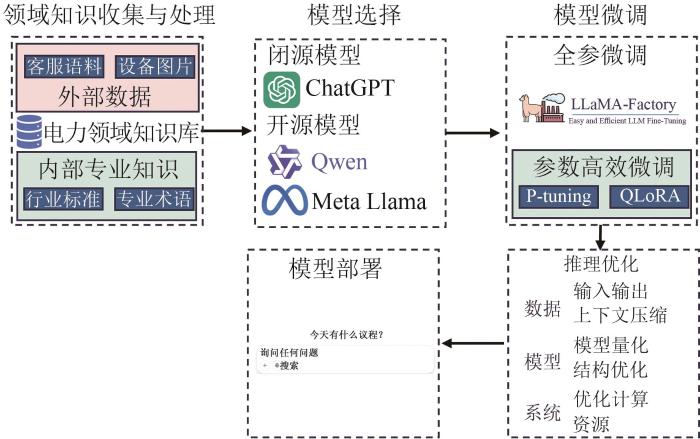
... 为保障核电领域知识和模型隐私安全,通常选择可本地部署的开源大语言模型,如LLaMa-3、Qwen2.5,当涉及图片等多模态数据时,可以选择MiniCPM-V 2.0[42],BLIP2[43]等多模态大语言模型. ...
BLIP-2:bootstrapping language-image pre-training with frozen image encoders and large language models
1
... 为保障核电领域知识和模型隐私安全,通常选择可本地部署的开源大语言模型,如LLaMa-3、Qwen2.5,当涉及图片等多模态数据时,可以选择MiniCPM-V 2.0[42],BLIP2[43]等多模态大语言模型. ...
P-tuning v2:prompt tuning can be comparable to fine-tuning universally across scales and tasks
1
... 现有微调方法主要有全参微调(full-parameter fine-tuning)和参数高效微调(parameter efficient fine-tuning).前者对整个预训练大语言模型进行微调,适用于任务和模型之间存在较大差异的情况,通常需要分布式全参微调.后者通常只更新模型的顶层或少数几层,目前主要以P-Tuning v2[44]、QLoRA[45]等算法为主.常用的大语言模型微调框架为LlamaFactory[46],支持多种开源大语言模型的分布式全参微调和参数高效微调算法.通过领域微调,可以大幅提高模型在核电领域的问答准确性和语义理解能力. ...
Qlora:efficient finetuning of quantized LLMs
1
2023
... 现有微调方法主要有全参微调(full-parameter fine-tuning)和参数高效微调(parameter efficient fine-tuning).前者对整个预训练大语言模型进行微调,适用于任务和模型之间存在较大差异的情况,通常需要分布式全参微调.后者通常只更新模型的顶层或少数几层,目前主要以P-Tuning v2[44]、QLoRA[45]等算法为主.常用的大语言模型微调框架为LlamaFactory[46],支持多种开源大语言模型的分布式全参微调和参数高效微调算法.通过领域微调,可以大幅提高模型在核电领域的问答准确性和语义理解能力. ...
LlamaFactory:unified efficient fine-tuning of 100+ language models
1
... 现有微调方法主要有全参微调(full-parameter fine-tuning)和参数高效微调(parameter efficient fine-tuning).前者对整个预训练大语言模型进行微调,适用于任务和模型之间存在较大差异的情况,通常需要分布式全参微调.后者通常只更新模型的顶层或少数几层,目前主要以P-Tuning v2[44]、QLoRA[45]等算法为主.常用的大语言模型微调框架为LlamaFactory[46],支持多种开源大语言模型的分布式全参微调和参数高效微调算法.通过领域微调,可以大幅提高模型在核电领域的问答准确性和语义理解能力. ...
A survey on efficient inference for large language models
1
... 在系统资源受限的场景下部署大语言模型,是当前实践应用面临的主要挑战,由于大语言模型参数量较大,注意力计算的复杂度较高,解码生成方式自回归,其在推理时的响应时间较长,因此,需要对大语言模型进行推理优化,以减轻应用系统的负担.文献[47]总结了主要的3种优化方向:1)数据层面,如压缩输入和输出的内容;2)模型层面,如模型量化和结构优化;3)系统层面,如优化服务系统和计算资源.这些优化方法在适度损失模型性能的条件下,可显著提升推理速度.对于微调后的大语言模型,可以通过Ollama、vLLM等[48]框架实现高效部署,以支持实际应用调用. ...
Efficient memory management for large language model serving with PagedAttention
1
2023
... 在系统资源受限的场景下部署大语言模型,是当前实践应用面临的主要挑战,由于大语言模型参数量较大,注意力计算的复杂度较高,解码生成方式自回归,其在推理时的响应时间较长,因此,需要对大语言模型进行推理优化,以减轻应用系统的负担.文献[47]总结了主要的3种优化方向:1)数据层面,如压缩输入和输出的内容;2)模型层面,如模型量化和结构优化;3)系统层面,如优化服务系统和计算资源.这些优化方法在适度损失模型性能的条件下,可显著提升推理速度.对于微调后的大语言模型,可以通过Ollama、vLLM等[48]框架实现高效部署,以支持实际应用调用. ...
ATLANTIC:structure-aware retrieval-augmented language model for interdisciplinary science
1
... 在构建领域知识库后,为将GRAG技术引入大语言模型,需要分别根据文档及其内容构建知识图谱.首先,以文档为知识图谱节点,以文档间的关系为边,构建具有跨文档且含全局信息的文档知识图谱[49].其次,对于文档内容,先将其分块,再应用命名实体识别和关系抽取工具(包括大语言模型)抽取实体和关系[50],以此构建含细粒度文档内容的知识图谱. ...
From local to global:a graph RAG approach to query-focused summarization
1
... 在构建领域知识库后,为将GRAG技术引入大语言模型,需要分别根据文档及其内容构建知识图谱.首先,以文档为知识图谱节点,以文档间的关系为边,构建具有跨文档且含全局信息的文档知识图谱[49].其次,对于文档内容,先将其分块,再应用命名实体识别和关系抽取工具(包括大语言模型)抽取实体和关系[50],以此构建含细粒度文档内容的知识图谱. ...
Retrieval-augmented generation for large language models:a survey
1
... 由于大语言模型存在幻觉问题,对于在大语言模型训练语料库中未曾出现的领域知识和实时更新的消息,大语言模型在回答时存在捏造事实、逻辑错误等问题.RAG技术通过引入外部知识,能够有效减少大语言模型的幻觉问题,增强大语言模型在下游任务中的表现[51]. ...
Graph indexing and querying:a review
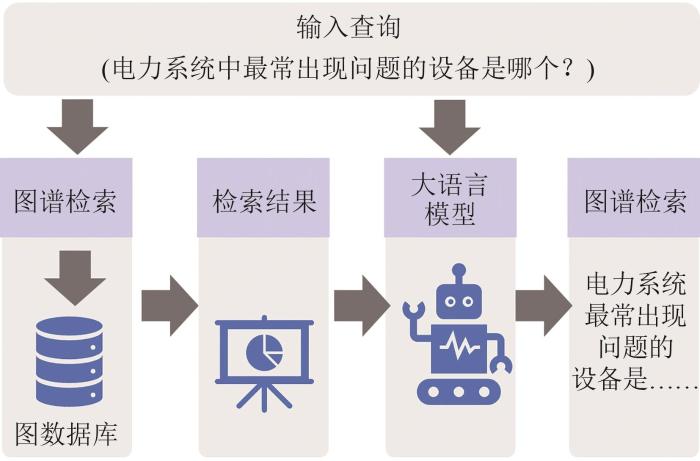
2
2010
... 然而,传统的RAG存在诸多问题,如冗余信息过长,忽略知识库全局的上下文信息等[52].而GRAG利用结构化知识图谱来减少无关的冗余信息,同时利用文档级的知识图谱提高大语言模型对外部知识的全局上下文理解能力.图4为知识图谱构建及GRAG技术在核电领域应用的一般技术路径. ...
... 为实现在知识库中快速检索与用户查询内容相关的信息,需要对构建的知识图谱建立索引.文献[52]介绍了主要的索引方法,包括直接基于图结构的索引、将图结构转化为文本的索引以及将图转化为嵌入向量的索引等;文献[53]从图结构出发,进一步总结了基于图中路径构建索引(GraphGrep);文献[54]使用频繁子图作为基本索引单元(GIndex);文献[55]则是采用基于图中关系的索引方式(GraphREL).这些索引方式能够提高检索效率,确保在用户查询时快速获取相关信息. ...
GraphGrep:a fast and universal method for querying graphs
1
2002
... 为实现在知识库中快速检索与用户查询内容相关的信息,需要对构建的知识图谱建立索引.文献[52]介绍了主要的索引方法,包括直接基于图结构的索引、将图结构转化为文本的索引以及将图转化为嵌入向量的索引等;文献[53]从图结构出发,进一步总结了基于图中路径构建索引(GraphGrep);文献[54]使用频繁子图作为基本索引单元(GIndex);文献[55]则是采用基于图中关系的索引方式(GraphREL).这些索引方式能够提高检索效率,确保在用户查询时快速获取相关信息. ...
Graph indexing:a frequent structure-based approach
2
2004
... 为实现在知识库中快速检索与用户查询内容相关的信息,需要对构建的知识图谱建立索引.文献[52]介绍了主要的索引方法,包括直接基于图结构的索引、将图结构转化为文本的索引以及将图转化为嵌入向量的索引等;文献[53]从图结构出发,进一步总结了基于图中路径构建索引(GraphGrep);文献[54]使用频繁子图作为基本索引单元(GIndex);文献[55]则是采用基于图中关系的索引方式(GraphREL).这些索引方式能够提高检索效率,确保在用户查询时快速获取相关信息. ...
... 检索阶段主要根据用户的查询信息,在索引数据库中提取与目标内容相关的信息,其检索结果对于大语言模型输出的内容质量起到关键作用.通常GRAG需对内容进行多粒度的检索,如子图、节点、路径等.其中,最重要的是基于子图的检索方式,常见的有基于启发式规则或图搜索的检索方式,如G-Retriever[56]直接基于节点间的语义相似度进行检索;此外,还有基于语言模型的检索方式和基于图神经网络的检索方式[54]. ...
GraphREL:a decomposition-based and selectivity-aware relational framework for processing sub-graph queries
1
2009
... 为实现在知识库中快速检索与用户查询内容相关的信息,需要对构建的知识图谱建立索引.文献[52]介绍了主要的索引方法,包括直接基于图结构的索引、将图结构转化为文本的索引以及将图转化为嵌入向量的索引等;文献[53]从图结构出发,进一步总结了基于图中路径构建索引(GraphGrep);文献[54]使用频繁子图作为基本索引单元(GIndex);文献[55]则是采用基于图中关系的索引方式(GraphREL).这些索引方式能够提高检索效率,确保在用户查询时快速获取相关信息. ...
G-retriever:retrieval-augmented generation for textual graph understanding and question answering
1
... 检索阶段主要根据用户的查询信息,在索引数据库中提取与目标内容相关的信息,其检索结果对于大语言模型输出的内容质量起到关键作用.通常GRAG需对内容进行多粒度的检索,如子图、节点、路径等.其中,最重要的是基于子图的检索方式,常见的有基于启发式规则或图搜索的检索方式,如G-Retriever[56]直接基于节点间的语义相似度进行检索;此外,还有基于语言模型的检索方式和基于图神经网络的检索方式[54]. ...
Extract,define,canonicalize:an LLM-based framework for knowledge graph construction
1
... 核电系统中的知识通常具有信息广泛性、多源异构特性,且有时伴有歧义、噪声与冗余.对于知识图谱构建,这些特性会造成有关实体、概念的属性描述缺乏精确性、一致性,或实体间关系错置、扭曲,使得图谱结构混乱及语义描述相互冲突,在图谱中产生大量孤立、无用的实体和属性关系,一定程度上稀释了数据信息内容和价值密度.由于多种影响因素之间可能存在复杂的相互关系和交叉影响,即使可以通过大语言模型辅助生成知识图谱,也使得模型在学习和预测时难以分辨各个因素的相对重要程度,导致最终的结果往往不佳,或者需要人工进行结果的校对,使得构建知识库的效率大大降低[57]. ...
Do large language models latently perform multi-hop reasoning?
1
... 核电领域的复杂推理也是一大难点,如需要进行多跳推理的问答.现有的大语言模型往往需要大量高质量的样本进行训练学习,需要耗费很大的代价才能具备一些基础的推理问答能力.而专家以及一线工作人员则可以依据先验知识与小样本数据,对核电拓扑以及运行数据进行分析判断.因而,如何高效利用核电领域原生数据来推动大语言模型的认知推理能力是一个重要课题.另外,如何保持对上下文的正确理解,进行有效的信息检索和融合,以及在不同核电场景下建立知识之间的关联并进行合理推理,都是亟待解决的问题[58]. ...
In-time explainability in multi-agent systems:challenges,opportunities,and roadmap
1
2020
... 目前,大语言模型技术仍处于初级阶段,模型的逻辑性和理解能力存在一定的偏差.由于大语言模型内部参数量庞大,其不可知的程度加深,决策过程的不可信性进一步增加了核电领域大语言模型应用的难度.在此基础上,可深入研究人机交互的AI智能体,这种智能体可与核电工作人员高效互动,实时获取核电领域资深专家的经验知识,并在复杂应用场景中发挥关键作用[59-63]. ...
Review of microgrid optimization operation based on deep reinforcement learning
0
2023
基于图神经网络和强化学习的电网风险态势感知
0
2023
GNN and RL based power system risk situation perception
0
2023
基于深度强化学习的电力系统紧急切机稳控策略生成方法
0
2025
Policy generation method for power system stability control during emergent tripping of unit based on deep reinforcement learning
0
2025
融合电网拓扑信息的分支竞争Q网络智能体紧急切负荷决策
1
2025
... 目前,大语言模型技术仍处于初级阶段,模型的逻辑性和理解能力存在一定的偏差.由于大语言模型内部参数量庞大,其不可知的程度加深,决策过程的不可信性进一步增加了核电领域大语言模型应用的难度.在此基础上,可深入研究人机交互的AI智能体,这种智能体可与核电工作人员高效互动,实时获取核电领域资深专家的经验知识,并在复杂应用场景中发挥关键作用[59-63]. ...
Emergency load shedding decision-making using a branching dueling Q-network integrating grid topology information
1
2025
... 目前,大语言模型技术仍处于初级阶段,模型的逻辑性和理解能力存在一定的偏差.由于大语言模型内部参数量庞大,其不可知的程度加深,决策过程的不可信性进一步增加了核电领域大语言模型应用的难度.在此基础上,可深入研究人机交互的AI智能体,这种智能体可与核电工作人员高效互动,实时获取核电领域资深专家的经验知识,并在复杂应用场景中发挥关键作用[59-63]. ...











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}