








0 引言
化石能源枯竭与气候环境危机加重,促使新型能源结构优化与供给方式的创新[1-3]。电力二次能源具备清洁、高效、便于传输和分配等特性,电力系统是能源互联网的核心模块已成为共识[4]。随着微电网、虚拟电厂、主动配电网等技术的发展,可再生能源作为推动能源结构转变的主要力量,大量分布式接入配电网,在配电侧引入了难以计数的可再生能源与电力系统的接口[5-6];电动汽车技术不断成熟与普及,使配电侧成为电力系统与交通系统交互的边界[7];小型燃气轮机、电转气、冷热电联供、储能等技术的发展[8],多种能源在电力系统的配电侧集中、交互,产生如随机波动、双向潮流等新特征,新技术不断涌现使配电网成为相比传统电网变化最多的领域,并将成为面向能源互联网未来电力系统中的关键环节[9]。未来新型配电网将成为电源集成、多流融合的能源互联网,多领域的融入、多专业的协作使得多人协同机制成为新型配电系统能源互联网规划的必经之路。基于异构数据库的同步技术是实现多人协同机制的核心[10];源端数据变更的捕获、目的端数据操作的辨识以及目的端数据同步是异构数据库同步技术的核心[11]。
源端数据的变更捕获大多采用基于触发器、变更(Tracking)表的捕捉方法。该方法适用于所有支持触发器的数据库系统,每个数据库下只需创建一张表,利用触发器将提取的变更信息存放于Tracking表中[12]。在使用中将所有的源端数据表和Tracking表一起打包发送至目的端,传输数据量较大[13]。目前,辨识数据“增、删、改”的主流技术是在源端数据库变更表中设置新增、更新、删除的标识用作区分[14]。从各目的数据库的角度和从源数据库的角度看数据的“增、改、删”是不同的,例如:某条记录对于许久不与源端同步的目的端A来说是需要新增的数据记录,而对于频繁与源端同步的目的端B来说是需要更新的数据记录,仅依靠操作标识解读容易造成混乱。同步数据的写入一般采用数据转换和解析技术,即将源端变更数据转换成XML格式的跨平台文档[15],目的端接受后按照目的数据库支持的操作语言解析成可执行语句并在目的端执行,从而将数据同步至目的数据库[16]。每条变更数据都要进行转换和解析,较为费时。
针对以上问题,本文在Microsoft Visual Studio.NET平台下,以Visual C#为开发语言开发出了一套新型异构数据库同步机制。在该同步机制中,将数据变更表与基础数据表相结合创建出临时表,传输仅保存有源端变更数据的临时表,大大减少了数据传输量。采用统一的组合编码(combination code)标识变更数据,各目的端数据库根据自身情况自行解析,避免解读混乱。在各目的端事先制定好各类数据操作的存储过程,省去了同类型操作语句的解析过程,提高了效率。
1 新型配电系统中多人协同机制
1.1 新型配电系统
与传统配电网相比,新型配电网存在许多新特性。电源侧,新能源的接入促进了配电系统能量来源的低碳化和多元化;电网侧,交直流混联技术、柔性配电技术及微电网技术等先进技术的应用,有效支撑了系统的源荷接纳能力;负荷侧,5G基站、新能源汽车等新型直流负荷的大量接入,将在不同的用电场景下形成差异化的可靠性需求[17]。
新型配电系统存在与交通网、天然气网等非电网网络在多时空状态下耦合的情况,且设备产权归属不一、生产厂商多样。新型配电系统中设备管理的数据不仅包含传统配电系统的设备参量、设备运行状态、网络潮流、工作环境状态,还应包含新型配电系统下的电动汽车、充电桩等电网资产以及用户储能、分布式电源等非电网资产[18]。
“双碳”背景下,配电网需要考虑大规模新型源荷及微网的接入,构建“上下协同”的新型配电网规划体系。“上下协同”的新型配电网规划体系是指以负荷用电需求为基础,目标网架为导向,将配电系统划分为不同层级,“上下协同”地开展系统规划,包括源荷预测、变电站选址定容、源荷储平衡单元划分等[17]。
1.2 多人协同机制
新型配电系统由电能分配者转变为能源交易服务者,成为区域能源优化协同平台、交易平台以及分布式能源接入和消纳平台。依托互联网,新型配电系统的多人协同机制,可实现无地域限制、人员归属不同部门、具有异构特性的软硬件资源通过网络连接实现数据同步和处理,从而达到任务按需分解、资源灵活调度、信息实时交换和任务高效集成等功能。
由此可见,基于异构数据库的数据同步技术是实现新型配电系统规划多人协同机制的核心;然而源端数据变更的捕获、目的端数据操作的辨识以及目的端数据库与源端数据库同步是异构数据库同步技术的关键。
2 同步准备
2.1 数据变更捕获
表1 Tracking表设计字段
Tab. 1
| 名称 | 类型 | 大小 | 比例 | 不能是NULL键 |
|---|---|---|---|---|
| 序号 | 唯一标识 | 0 | 0 | √ |
| 表名 | 字符串 | 200 | 0 | |
| 时间戳 | 时间 | 0 | 0 | |
| 更改时间 | 时间 | 0 | 0 | |
| 删除 | 字符串 | 200 | 0 | |
| 用户名 | 字符串 | 200 | 0 | |
| 组合编码 | 字符串 | 200 | 0 | |
| 变化字段 | 变长字符串 | 0 | 0 |
表2 Tracking表记录
Tab. 2
| 序号 | 表名 | 更改时间 | 删除 | 用户名 | 组合编码 | 变化字段 | 单位序号 |
|---|---|---|---|---|---|---|---|
| 55A4AF25-F5BA | 配电设施表 | 2021-10-31 12:02:02.250 | 73457EB2-FF21-4D34 | 73457EB2-FF21-4D34 | |||
| OE2BF150-AAF2 | 线路表 | 2021-10-31 12:16:49.480 | 73457EB2-FF21-4D34 | 73457EB2-FF21-4D34 |
序号是Tracking表的主键;表名是发生变更事件的数据表的名称;更改时间记录了数据变更发生的时刻;用户名是使数据库表发生数据变更的用户;组合编码是发生变更数据的唯一标识。新型配电网能源互联网网格化规划系统中包含各种用户表,如表3所示。
表3 新型配电网网格化规划系统中的各数据表
Tab. 3
| 序号 | 表名 | 修改时间 |
|---|---|---|
| 1 | 变电站表 | 2021-10-31 16:57:26.533 |
| 2 | 单位信息表 | 2021-10-31 16:57:26.490 |
| 3 | 地区概况表 | 2021-10-31 16:57:26.463 |
| 4 | 地下廊道表 | 2021-10-31 16:57:26.467 |
| 5 | 典型参数表 | 2021-10-31 17:15:19.703 |
| 6 | 电力平衡表 | 2021-10-31 17:15:19.707 |
| 7 | 电网指标表 | 2021-10-31 16:57:26.250 |
| 8 | 电源表 | 2021-10-31 16:57:26.530 |
| 9 | 方案比选表 | 2021-10-31 16:57:26.470 |
| 10 | 负荷电量表 | 2021-10-31 16:57:26.503 |
| 11 | 高压线路表 | 2021-10-31 16:57:26.489 |
| 12 | 高压项目库表 | 2021-10-31 16:57:26.980 |
| 13 | 供电分区表 | 2021-10-31 16:57:26.760 |
| 14 | 关联设备表 | 2021-10-31 16:57:26.780 |
| 15 | 开关设施表 | 2021-10-31 16:57:26.593 |
每个数据表中的字段不尽相同,因此Tracking表中组合编码字段的表示方式也不相同。对于未设置“ID”字段数据表,组合编码就以“Serial number”字段标识;对于未设置“Serial number”的数据表,组合编码就以“ID”记录;对于大部分常规数据表,组合编码采用“Unit serial number + year + ID”的形式记录;对于个别特殊的数据表,组合编码可根据需要选用合适的几种字段标识。不论情况如何,都必须保证它是变更数据的唯一标识。
主数据库位于核心位置,是数据交换的中心,系统中的其他数据库均为从数据库,只与主数据库进行交换,相互之间不能直接通信,需要经由主数据库与其他的从数据库进行数据交换。“拉模式”是指需要进行数据同步的从数据库主动向主数据库发送同步请求,主数据库接收到请求后,将同步数据发送到目标数据库中[18]。每个从数据库中的同步数据通过“拉模式”与主数据库进行交换。该方法实现起来简单方便,减少了源数据库的数据传输量,虽然在同步的效率和实时性方面的效果不如“推模式”,但对于新型配电系统能源互联网规划的多人协同来说,时间精度是足够的。这就导致更新、插入、删除操作对不同从数据库来说是不一样的,例如某条数据对一个很久没与主数据库同步的从数据库来说是新增数据,但对于经常同步的从数据库来说是更新数据。因此,Tracking表中无需设置标识更新、插入、删除的标志位。平台采用的触发同步模式为“主从数据库+拉模式”,执行同步的过程中,才会使用“推拉”相结合的模式。
当数据表中数据变化较少时,采用触发器在Tracking表中插入变更数据的模式,这种模式对运行效率影响较小。批量修改数据时,为避免频繁启用触发器导致运行速度减慢,软件内置了优化算法,即当明确知道数据表中数据更新量大且规律时,禁用触发器,自动在Tracking表中插入数据,变更Tracking记录行并更新变化时间。
2.2 数据异构的处理
数据库的异构性主要体现在数据库管理系统异构(包含结构异构、规则异构和查询语言异构)、语义异构(包含命名异构和数据存储类型异构)。结构异构表现为相同数据类型在源数据库与目的数据库之间存在长度、精度、数据存储格式之间的差异。语义冲突表现在源数据库中2个以上表的字段与目的数据库同一表中字段对应,或相同含义的表、字段在源数据库与目的数据库中名称不同[23]。
本系统采用“基于XML技术的数据映射表+C#程序处理+用户设置”的方式来解决上述异构性问题。基于XML技术的数据映射表技术较为成熟,是主从数据库之间的桥梁,能够解决异构数据库之间存在的多种冲突问题。建立数据映射表时,主数据库依次连接每个从数据库,获取从数据库中所有用户表的结构信息,并分别与自身数据库结构信息进行比对,为数据结构转换做好准备。根据源数据库表和目的数据库表的元数据,建立数据映射(MappingFile.xml)表,如表4所示。
表4 数据映射表
Tab. 4
| 名称 | 类型 | 注释 |
|---|---|---|
| ID | Nvarchar(100) | 从数据库ID |
| DatabaseType | Nvarchar(100) | 从数据库类型 |
| MainTableName | Nvarchar(100) | 主数据库表名 |
| SlaveTableName | Nvarchar(100) | 从数据库表名 |
| MainFieldName | Nvarchar(100) | 主数据库表字段名 |
| SlaveFieldName | Nvarchar(100) | 从数据库表字段名 |
| MainFieldType | Nvarchar(100) | 主数据库表字段类型 |
| SlaveFieldType | Nvarchar(100) | 从数据库表字段类型 |
| MasterTableConstraints | Nvarchar(100) | 主数据库表约束 |
| SlaveTableConstraints | Nvarchar(100) | 从数据库表 |
| AddTime | datetime | 添加时间 |
| IsDeleted | Nvarchar(2) | 是否删除 |
当源表之间存在主外键约束时,数据映射表中还需包括源表名称、主键,以及附表名称、外键;当目的表之间存在主外键约束时,也需要将这些约束字段包含进来[24]。
映射原则为:如果表名、字段名不存在命名冲突,则目的数据库表名、字段名与源数据库表名、字段名相同;否则目的数据库表、字段名称需按照规则修改为新的名称。若遇到XML技术不易处理的数据类型,例如时间日期格式,需要在 .NET平台中采用C#语言自定义专用的转换程序协助数据类型转换,如图1所示。若遇到难以确定的特殊情况,还需要用户手动进行匹配。
图1

2.3 同步模式与同步形式选择
2.3.1 同步模式选择
主从数据库的数据同步模式分为2种:全量式数据同步模式和增量式数据同步模式。
1)全量式数据同步模式是将源数据库中的数据完整地迁移至目的数据库中。该模式适用于目的数据库为空、内容较少或长时期未与主数据库同步的情景,其同步颗粒度为整条数据记录。
2)增量式数据同步模式是指目的数据库已经存在的数据,需要建立源数据库结构与目的数据库结构的对应关系,按照结构对应关系的设置将源数据库数据插入或更新到目的数据库,源数据库与目的数据库中重复的数据不进行更新。该模式适用于目的数据库经常与主数据库同步的情景,其同步颗粒度为字段。
2.3.2 同步形式选择
数据库表记录变化分为2种类别:整张数据表整体变化和部分字段局部变化。相应地,数据同步形式分为整表同步形式和字段同步形式。
新型配电系统能源互联网网格化规划平台采用左表右图的结构。在进行图形数据编辑时,能够实现图数联动功能,即如果左侧结构树(对应数据库中的台账数据)中发生变化,那么右侧绘图窗口中的图形(对应着数据库中的图形数据,如图例、标注、颜色、大小、位置等)将联动发生相应变化;右侧绘图窗口中的图形被删除,那么左侧结构树中该设备也会自动移除。
数据同步形式的选择以多人协同工作时事务之间是否相互影响为标准,每次同步时一张数据表只能选择一种同步方式,具体如下:
1)台账数据与图形数据无需相互联动的表采用全量式同步模式。例如地区概况表,只用于记录区域概况数据,与图形数据不关联,采用整表同步形式,同步颗粒度为整张数据表。
2)涉及台账数据和图形数据相互联动的表采用字段同步模式。例如变电站表,表中的数据是需要和绘图区域的图形数据(如变电站图标、位置、颜色、大小)相互对应的,这就需要达到字段同步效果,必须选择字段同步形式,同步颗粒度为数据表中的一个字段。
3)多人协作时,若一人修改台账数据(如修改负荷数据),另一人编辑图形数据(如修改配电设施图标位置、颜色),这2项工作互不影响,系统会选择整表同步模式。若2人均在绘图窗口中编辑图形数据(如修改图标位置、颜色),这2项工作存在一定程度的关联,系统会选择字段同步形式,将2人所做的修改整合起来。
3 同步实现
3.1 主数据库的数据同步
同步操作以主数据库为中转站和汇集站,整合多个从数据库的变更数据,汇集筛选所有变化数据形成最新数据池、记录数据变化的时间,并将这些变化数据全部整合到主数据库对应的表中。主数据库对数据的整合原则如下:
1)根据每次同步完成所记录的变化时间,整合一定时间段的所有数据变化。这个时间段是上次同步成功之后到这次同步之前,是不固定的。
2)若变更的数据为不同数据表或为同一数据表的不同字段,则依照时间顺序对数据进行整合。整合时通过ID识别数据记录,若ID相同,表明为同一条记录,意味着存在重复数据,这时用变更时间最新的数据记录覆盖旧的数据记录。
3)若变更的数据为同一数据库表中的同一字段,则对比各个从数据库上送的Tracking表,以变更时间最新的记录为准。
4)主数据库在同步数据期间,启动缓存机制和锁机制,保证同步操作在一定的时间内完成,且同步过程中任何从数据库都不能读取主数据库中的数据。
为减少开销,主数据库的Tracking表需要定期清理。为避免每次清理时主数据库都要判别是否所有从数据库都成功把某段时间的变更数据全部同步了,可采用定时清理的模式。例如:设置每月定时清理一次Tracking表,如果某个从数据库同步时,发现与主数据库的时间差超过了一个月,则说明该从数据库中的数据陈旧,需要从主服务器中下载全部最新的数据。
采用基于共享方式的双机热备,一主一备,均定时从公共区域获取数据,避免瞬时压力过大导致服务器宕机等灾难性情况致使数据丢失。通过检测心跳监测主数据库是否断网,若主数据库断网,则备用数据库立即作为主数据库启用。
3.2 从数据库的数据同步
从数据库主动向主数据库发送同步请求的过程如下:
1)准备变更数据。从数据库将本地数据库中的变更数据(当前时刻距上一次同步成功后的数据)从本地Tracking表中抽取出来。
2)向主数据库发送同步请求,得到主数据库返回的远程Tracking表。
3)从数据库对来自主数据库中的Tracking表数据和本地Tracking表数据进行对比,基于修改时间判断同步的方向。若某条记录只在远程Tracking表中存在,而在本地Tracking表中不存在,表明该记录是新增数据,需要从主数据库同步到本地。若某条记录在主服务器Tracking表和本地Tracking表中均存在,且主服务器Tracking表的更新时间更新,表明该记录为更新或删除数据,需要从主数据库同步到本地;反之,需要从本地同步到主数据库。
4)比对完Tracking表后,从数据库首先对本地数据进行整合。整合过程中,从数据库禁用触发器,即不需要获取数据变化的时间。整合完毕,再将本地更新数据上传到主数据库,主数据库根据获取的所有从数据库数据进行整合。
3.3 临时表与数据传输
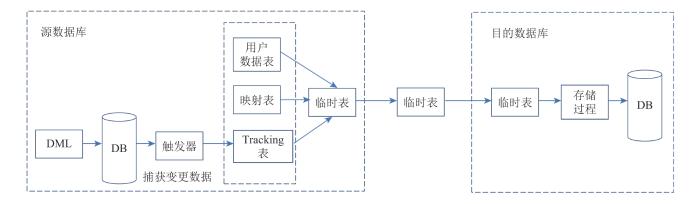
为最大限度地减少网络传输的数据量,仅传输所有变更的数据记录,通过创建临时表保存本地所有变更数据。
各个数据库将本地的Tracking表与用户数据表进行左连接(Left join),即可得到各自所有存在变更的数据记录;将此记录在.NET平台用C#语言创建为临时表,表的格式与各个数据库表的格式(字段等元数据)完全一致。
ActiveX数据对象(ActiveX data objects,ADO)是一个以 Microsoft.NET框架为基础的数据操作模型,专门为Microsoft.NET平台上的数据访问而设计。ADO.NET用于建立数据库之间的连接。
ADO.NET通过Connection、Command、DataSet等对象实现数据库操作。实际应用中可根据需要添加数据库操作类来扩展数据转换工具支持的数据库类型。临时表的创建及数据传输都在 .NET平台上实现,流程见图2。
图2
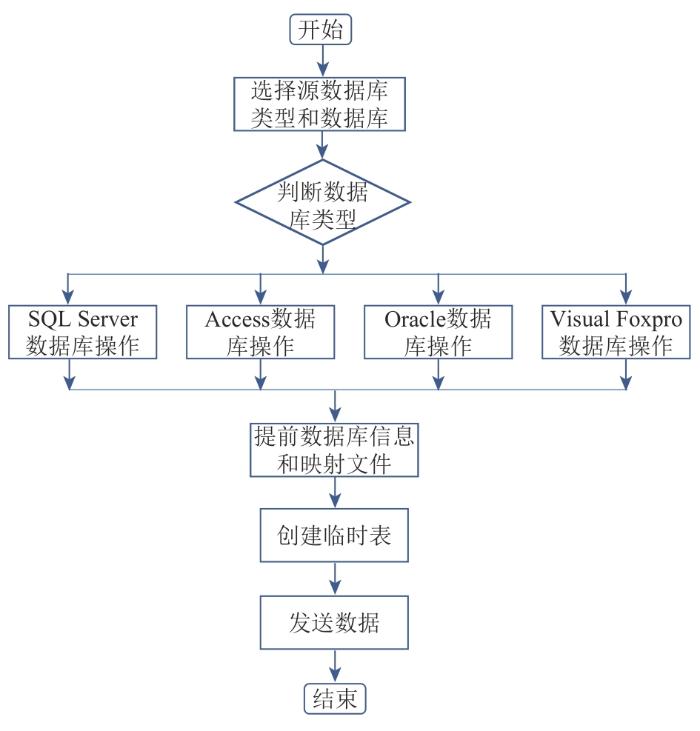
以源数据库为SQL Server数据库为例,SQL Server数据库支持批量数据传输,.NET平台的SqlBulkCopy类是.NET平台与SQL Server数据库的接口,可通过它向 SQL Server数据库写入数据。具体步骤如下:
1)初始化数据类型。一般使用目的数据库中的列名作为列名,按照数据映射文件与需要导入源表的列名进行匹配。
2)设置参数。如每次最多能装入多少条临时表数据、设置为同步传输模式还是异步传输模式、是否需要放开约束(例如装入数据时不检查约束)。
3)按照设置的参数添加数据。
4)传输临时表中的数据。
3.4 同步数据写入
同步数据写入功能就是根据接收到的临时表,将源数据库的数据写入目的数据库以完成数据同步的过程。
由于源数据库在生成临时表时已经做好了数据映射。目的数据库将临时表中的变更数据转换为本数据库支持的操作语句并执行,即完成了数据同步。
实际应用中,对数据表的操作有插入、删除、主键更新、非主键更新4种情况,且数据库操作语句结构大致相同,所以在每个数据库中均预先配置了实现这4种操作的存储过程,只要对照临时表调用相应的存储过程即可。
需要注意的是,为了避免出现“同步振荡”,需判断当前用户是否为登录该平台数据库的用户,而非数据库本身。如果为数据库本身,则触发器禁用;否则,触发器启用并将提取的控制信息插入到Tracking表中。数据同步的整个过程如图3所示。
图3
3.5 冲突的处理
本平台为每个从数据库提供统一操作界面,同一时刻可能有多个用户进行协同操作。用户之间的事务冲突是最主要的冲突,解决冲突是保证系统正常运行的关键所在,须采取有效的方法。
由于事务具有原子性、一致性、持续性、隔离性,因此将各用户的操作放在事务中。例如:用户A进行事务S1操作,用户B进行事务S2操作,事务S1操作远程数据库C1,事务S2操作远程数据库C2,若事务S1的操作需要用到事务S2操作的数据,事务S2需要用到事务S1操作的数据,就会出现“死锁”的状态。
冲突处理的裁决机制分为根据操作时间判定、根据用户节点的优先级判定、根据用户的级别判定等。使用中,根据不同的协同场景,选用不同的机制。
4 数据库备份与还原
为确保数据的安全,同步之前需要对数据库进行备份,备份文件为在本地数据库生成的.bak文件。数据库的还原和备份由.NET平台实现。
同步数据过程(“推拉”结合模式)执行2个事务:事务1是从数据库检测到主数据库中有变更数据,将变更数据下载到本地;事务2是从数据库将自身的变更数据推送给主数据库,进行变更数据的更新上传。这2个事务一同提交,更新成一致的同步时间,同步过程才算成功完成。
如果同步过程发生由于网络或者其他原因造成的中断,则停止所有操作,事务回滚,即从数据库回滚到本地数据库提交事务之前,主数据库回滚到自身数据变化之前,等待下一次同步操作,并保存同步操作记录。
如果需要校验回滚后的数据是否为同步之前的数据,可以利用数据库的备份机制进行检测,即将.bak文件恢复,看看回滚后数据是否与备份文件相同。
5 结论
在 Microsoft Visual Studio.NET平台下开发了一套新型异构数据库同步机制,应用于株洲市新型配电系统能源互联网网格化规划软件的多人协同机制中,使得常规需要3人2个月完成的协作任务缩短至2人1个月完成。得到以下结论:
1)在触发器和数据变更表的基础上进一步创建出临时表,仅将获取到的源端变更数据保存在临时表中,传输过程中也仅传输临时表,大大减少了数据量。
2)在数据辨识的实现上不使用新增、更新、删除标识,而是在源端统一用组合编码标识变更数据,在目的端数据库中各自进行解析,避免了解读的混乱。
3)在数据的同步方面,通过Tracking表和临时表事先定制好对目的数据库进行各类操作的存储过程,执行数据同步时只需调用相应的存储过程,省去了同类型语句的解析时间,提高了效率。
4)采用“基于XML技术的数据映射表+C#程序处理+用户设置”的方式共同解决各种数据库异构性问题。
然而,开发的同步机制也存在一定的局限性,后续工作中,将在以下方面进行拓展和改进:
1)可以设定系统传送时间,采用“推模式”使主数据库主动向各个从数据库传送变更数据,以实现准实时数据同步。
2)将生成的临时表封装成SOAP消息,通过Web Services传送到主数据库中,并通知主数据库同步数据已经传送。在SOAP消息的头部加入源数据库的信息和目标数据库的地址、登录名、密码等信息,通过Web服务传送到目标数据库中。
3)未来随着清洁能源集成、多流融合、多领域融入、多专业协作的不断深化,基于不同原理实现的数据库必定越来越多。如果某些数据库不支持触发器,程序将无法捕获变化数据,数据同步就无法实现,因此,需考虑采用更加先进、适应性更强的数据同步机制以实现不支持触发器机制的数据库同步。
参考文献
Grid 2030:a national vision for electricity’s second 100 years
[J].
低碳电力技术的研究展望
[J].
Prospects of low-carbon electricity
[J].
双碳目标下储能系统关键技术及应用
[J].
Key technology and application of energy storage system under double carbon target
[J].
能源互联网背景下电网备用问题探索
[J].
Research on reserve services of the power grid under the background of energy Internet
[J].
AC and DC technology in microgrids:a review
[J].
A novel demand response model with an application for a virtual power plant
[J].
综合能源系统环境下电动汽车分群优化调度
[J].
Optimal scheduling of electric vehicle clusters in integrated energy system
[J].
太阳能综合利用的冷热电联供系统控制策略和运行优化
[J].
A control strategy and operation optimization of combined cooling heating and power system considering solar comprehensive utilization
[J].
面向能源互联网的未来综合配电系统形态展望
[J].
Outlook of future integrated distribution system morphology orienting to energy Internet
[J].
基于XML的异构数据库数据转换工具的设计与实现
[D].
Design and implementation of a XML-based data transformation tool between heterogeneous databases
[D].
分布式异构数据库同步更新的研究与应用
[D].
Researchon and application of synchronization update of distributed heterogeneous database
[D].
基于Web服务的分布式异构数据库增量同步更新应用研究
[D].
Research and application of distributed heterogeneous database incremental synchronization update based on web service
[D].
异构数据库数据同步的关键技术研究
[D].
The key technology research of data synchronization on heterogeneous database
[D].
异构数据库同步系统设计与应用
[D].
Design and application of heterogeneous database synchronization system
[D].
异构数据库系统信息同步触发更新技术研究
[D].
Research of synchronized trigger and update technology between heterogeneous relational database systems
[D].
分布式异构数据库同步系统的研究与应用
[J].
Implementation of synchronization system for distributed
[J].
“双碳”目标下新型配电系统功能形态及规划体系
[J].
ZHANG X D,GAO Q,PAN H. Function,form and planning system of novel power distribution system with "double-carbon" goal
[J].
新型配电系统形态特征与技术展望
[J].
Morphological characteristics and technology prospect of new distribution system
[J].
协同工作中冲突消解机制的研究
[J].
Collaborative work in conflict resolution mechanism
[J].
知识网格环境下多任务模型协同工作机制研究
[J].
Research on the collaborative work mechanism of the multi-task model in knowledge grids
[J].
数据库同步中差异数据捕获方案设计与实现
[J].
Database synchronization data capture differences in program design and implementation
[J].
数据同步技术在高校数据中心的应用
[J].
Application of data synchronization technology in university data center
[J].
一种异构关系型数据库间的数据同步方案
[J].
A data synchronization scheme between heterogeneous relational databases
[J].
异构数据库同步技术的研究与实现
[J].
Research and implementation of synchronization technology of heterogeneous database
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}